머신러닝에 있어, 가장 먼저해야 하는 일 중 하나가 데이터 정제(Data Cleaning)입니다.
왜냐하면 바로 모델을 훈련할 수 있는 데이터셋을 확보하는 것이 실제로는 매우 어렵기 때문입니다.
따라서, 결측값(NaN)은 없는지, 이상치(outlier)는 없는지 알아보기 위해 데이터셋을 주의깊게 살펴보아야 합니다.
값이 큰 열이 있는 경우 정규화를 통한 보정이 필요하기도 합니다.
이번에는 데이터 정제(Data Cleaning)에 필요한 일반적인 작업에 대해 알아보도록 하겠습니다.
결측값(NaN)이 있는 열 정제하기
다음 데이터로 된 NaNDataset.csv 파일이 있다고 가정하겠습니다.

눈으로 봐도 몇개 열에 결측값이 있는 것을 확인할 수 있습니다.
작은 데이터셋에서는, 쉽게 결측값을 찾을 수 있습니다.
하지만, 큰 데이터셋에서는, 눈으로 알아내는 게 거의 불가능할 것입니다.
결측값을 찾아내는 효과적인 방법은 판다스(Pandas) 데이터프레임으로 데이터셋을 로드해서 데이터프레임의 빈 값(NaN) 여부를 확인하기 위해 isnull() 함수를 사용하는 것입니다.
>>> import pandas as pd
>>> df = pd.read_csv('NaNDataset.csv')
>>> df.isnull().sum()

B 컬럼에 두개의 빈 값이 있는 것을 볼 수 있습니다.
판다스(Pandas)에서 빈 값이 포함된 데이터셋을 로드할 때, 빈 필드를 나타내는 NaN을 사용할 것입니다.
다음은 데이터프레임의 결과물입니다.
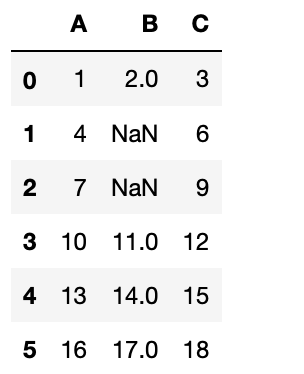
컬럼의 평균값으로 NaN 대체하기
데이터셋의 NaN(빈 값)을 처리하는 방법 중 하나는 그 빈 값이 위치한 컬럼의 평균값으로 빈 값을 대체 처리하는 것입니다.
다음의 스니펫 코드는 B 컬럼의 모든 빈 값(NaN)을 B 컬럼의 평균값으로 대체합니다.
>>> df.B = df.B.fillna(df.B.mean()) # NaN(빈 값)을 B 컬럼의 평균값으로 대체합니다.
>>> df

열 제거하기
데이터셋에서 빈 값(NaN)을 처리하는 다른 방법은 빈 값이 포함된 열을 제거하는 것입니다.
아래와 같이 dropna() 함수를 사용해서 처리할 수 있습니다.
>>> df = pd.read_csv('NaNDataset.csv')
>>> df = df.dropna()
>>> df

NaN이 포함된 행을 제거한 후에 인덱스 순번이 더 이상 맞지 않는다는 것을 알 수 있습니다.
인덱스를 재설정하고 싶다면, reset_index() 함수를 사용합니다.
>>> df = df.reset_index(drop=True) # 인덱스를 재설정합니다
>>> df
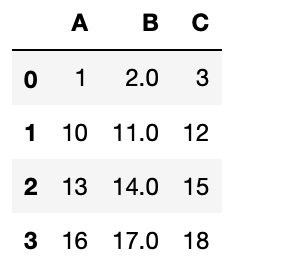
중복된 열 제거하기
다음 데이터로 된 DuplicateRows.csv 파일이 있다고 가정하겠습니다.

중복된 모든 열을 찾기 위해, 먼저 데이터셋을 데이터프레임에 로드합니다.
그리고, duplicated() 함수를 적용합니다.
>>> df = pd.read_csv('DuplicateRows.csv') # 판다스(Pandas) 라이브러리는 이미 로드했다고 가정합니다.
>>> df.duplicated(keep=False))

어떤 열이 중복되었는지 알려줍니다. 위 예에서는, 인덱스 1, 2, 5, 6열이 중복입니다.
keep 인수를 사용하면 중복을 표시하는 방법을 지정할 수 있습니다.
- 기본값은 'first' : 첫번째 나타나는 것을 제외한, 모든 중복이 True로 표시됩니다.
- 'last' : 마지막으로 나타나는 것을 제외한, 모든 중복이 True로 표시됩니다.
- False : 모든 중복이 True로 표시됩니다.
만약 keep 인수를 'first'로 설정하면, 다음과 같은 결과물을 보게 될 것입니다:

따라서, 모든 중복 열들을 보고 싶다면, keep 인수를 False로 설정해야 합니다.
>>> df[df.duplicated(keep=False)]

중복 행을 삭제하려면 drop_duplicates() 함수를 사용할 수 있습니다.
>>> df.drop_duplicates(keep='first', inplace=True) # 처음 열은 그대로 두고, 그 다음 중복 열만 제거합니다.
>>> df

기본적으로, drop_duplicates() 함수는 원본 데이터프레임을 수정하지 않고, 제거된 열이 포함된 데이터프레임을 반환합니다.
만약 원본 데이터프레임을 수정하고 싶다면, inplace 파라미터를 True로 설정해야 합니다.
때로는 데이터셋의 특정 열에서 발견된 중복만 제거하고 싶은 경우가 있습니다.
예를 들어, 3, 4열의 B컬럼은 값이 다르지만, A, C 컬럼은 동일합니다. 이를 기준으로 제거해 보도록 하겠습니다.
>>> df.drop_duplicates(subset=['A', 'C'], keep='last', inplace=True) # A, C 컬럼에 모든 중복을 제거하고, 마지막 열을 남깁니다.
>>> df

컬럼 정규화하기
정규화는 데이터 정리 프로세스 중에 자주 적용되는 기술입니다.
정규화의 목적은 데이터 범위의 숫자 열 값을 변경하여, 값 범위의 차이를 수정하지 않고 공통 척도를 적용하는 것입니다.
일부 알고리즘은 데이터를 올바르게 모델링하기 위해 정규화가 중요합니다.
예를 들어, 데이터셋 열 중 하나는 0에서 1까지의 값을 포함하고 다른 열은 400,000에서 500,000까지의 값을 가질 수 있습니다.
두 개의 열을 사용하여 모델을 훈련하면 숫자의 척도가 크게 달라질 수 있습니다.
정규화를 사용하면 두 열의 값 비율을 제한된 범위로 유지하면서 값의 비율을 유지할 수 있습니다.
판다스(Pandas)에서는 MinMaxScaler 클래스를 사용하여 각 열을 특정 값 범위로 확장할 수 있습니다.
다음 데이터로 된 NormalizeColumns.csv 파일이 있다고 가정하겠습니다.

다음 스니펫 코드는 모든 열의 값을 (0,1) 범위로 조정합니다.
>>> import pandas as pd
>>> from skleran import preprocessing
>>> df = pd.read_csv('NormalizeColumns.csv')
>>> x = df.values.astype(float)
>>> min_max_scaler = preprocessing.MinMaxScaler()
>>> x_scaled = min_max_scaler.fit_transform(x)
>>> df = pd.DataFrame(x_scaled, columns=df.columns)
>>> df
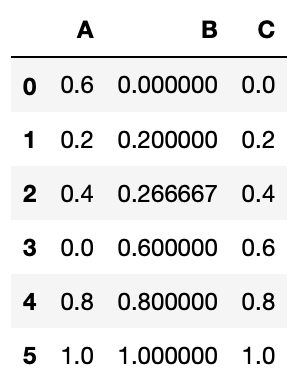
이상치(outlier) 제거하기
통계에서 이상치(이상점, outlier)는 관측된 다른 점들과 먼 지점의 점입니다.
예를 들어, 다음과 같은 값들(234, 267, 1, 200, 245, 300, 199, 250, 8999, 245)이 세트로 주어졌다고 하면, 이 중에서 명백하게 1과 8999는 이상치(oulier)입니다.
그들은 나머지 값들과 뚜렷이 구별되며, 데이터셋의 대부분의 다른 값들과 달리 "바깥에 위치합니다".
이상치는 주로 기록 또는 실험 오류의 오류로 인해 발생하며 머신러닝에서는 모델을 학습하기 전에 이상치를 제거해야 합니다.
그렇지 않으면 모델을 왜곡시킬 수 있습니다.
이상치를 제거하는 데는 여러 가지 기술이 있으며,이번에서는 두 가지를 논의합니다.
- Tukey Fences
- Z-Score
Tukey Fences
Tukey Fences는 사분위 범위(IQR, interquartile range)를 기반으로 합니다.
Q1이라고 표시된 첫번째 사분위수는 데이터셋의 값 중 첫번째 25 %를 보유하는 값입니다.
3분위수(Q3)은 데이터셋의 값 중 3번째의 25 %를 보유하는 값입니다.
따라서, 정의에 따르면, IQR = Q3-Q1입니다.
아래 그림은 짝수 및 홀수 값을 가진 데이터셋에 대해 IQR을 얻는 방법의 예를 보여줍니다.

Tukey Fences에서 이상치(outlier)는 다음과 같은 값입니다.
- Q1 - (1.5 * IQR) 미만 or
- Q3 + (1.5 * IQR) 초과
다음 스니펫 코드는 파이썬을 사용해 Tukey Fences를 실행하는 방법을 보여줍니다.
>>> import numpy as np
>>> def outliers_iqr(data):
q1, q3 = np.percentile(data, [25, 75])
iqr = q3 - q1
lower_bound = q1 - (iqr * 1.5)
upper_bound = q3 + (iqr * 1.5)
return np.where((data > upper_bound) | (data < lower_bound))
np.where() 함수는 조건에 만족하는 아이템들의 위치를 반환합니다.
outliers_iqr() 함수는 첫 번째 요소가 이상치(oulier)값을 갖는 행의 인덱스 배열인 튜플을 반환합니다.
Tukey Fences를 테스트하기 위해, 부모와 자녀의 키에 대해 유명한 Galton 데이터셋을 사용해 보도록 하겠습니다.
이 데이터셋에는 Francis Galton이 1885년에 실시한 유명한 아동 연구결과를 기반으로 한 데이터가 포함되어 있습니다.
각각의 경우는 성인용이며 변수는 다음과 같습니다.
- Family : 자녀가 속한 가족으로서 1에서 204 사이의 숫자와 136A로 표시됩니다.
- Father : 아빠의 키(인치)
- Mother : 엄마의 키(인치)
- Gender : 아이들의 성, 남성(M) 또는 여성(F)
- Height : 아이들의 키(인치)
- Kids : 아이들의 가정에서, 아이들의 숫자
이 데이터셋은 898 케이스를 갖고 있습니다.
먼저 데이터를 읽어들입니다:
>>> import pandas as pd
>>> df = pd.read_csv('http://www.mosaic-web.org/go/datasets/galton.csv')
>>> df.head()

height 컬럼에서 이상치(outlier)를 찾고 싶다면, 다음과 같이 outliers_iqr() 함수를 불러옵니다.
>>> print('Outliers using ourliers_iqr()')
>>> print('=====================')
>>> for i in outliers_iqr(df.height)[0]:
print(df[i:i+1])
다음과 같은 결과를 볼 수 있습니다:

Tukey Fences 메서드를 사용해, height 컬럼에 하나의 이상치(outlier)가 있다는 것을 알 수 있었습니다.
Z-Score
이상치(outlier)를 결정하는 두번째 방법은 Z-Score 메서드를 사용하는 것입니다.
Z-Score는 데이터 포인트가 평균에서 얼마나 많은 표준 편차를 가지는지 나타냅니다.
Z-Score의 공식은 다음과 같습니다.

여기서 xi는 데이터 포인트, μ는 데이터셋의 평균, σ는 표준편차입니다.
- 음의 Z-Score는 데이터 포인트가 평균보다 작음을 나타내고 양의 Z-Score는 문제의 데이터 포인트가 평균보다 큰 것을 나타냅니다.
- Z-Score가 0이면 데이터 포인트가 중간(평균)이고 Z-Score가 1이면 데이터 포인트가 평균보다 1 표준편차가 높다는 것을 알 수 있습니다.
- 3보다 크거나 -3보다 작은 모든 Z-Score는 이상치(outlier)로 간주됩니다.
다음 스니펫 코드는 파이썬을 사용해 Z-Score를 실행하는 방법을 보여줍니다.
>>> def outliers_z_score(data):
threshold = 3
mean = np.mean(data)
std = np.std(data)
z_scores = [(y - mean) / std for y in data]
return np.where(np.abs(z_scores) > threshold)
이전에 사용한 것과 동일한 Galton 데이터셋에 대해 outliers_z_score()함수를 사용해 height 컬럼에 대한 이상치(outlier)를 찾을 수 있습니다.
>>> print('Outliers using ourliers_z_score()')
>>> print('=========================')
>>> for i in outliers_z_score(df.height)[0]:
print(df[i:i+1])
다음과 같은 결과물을 볼 수 있습니다.

Z- Score 메서드를 사용하면 height 컬럼에 3개의 이상치(outlier)가 있음을 알 수 있습니다.
(Source : Python Machine Learning, Wiley, 2019)
'파이썬으로 할 수 있는 일 > 머신러닝' 카테고리의 다른 글
| Transformer의 기본 구조 (0) | 2022.02.10 |
|---|---|
| 머신러닝 용어들(NLP, CV) (0) | 2021.07.19 |
| 선형 회귀분석(Linear Regression) : 사이킷런(Scikit-learn) 기초 (0) | 2019.05.23 |
| 데이터셋 획득 : 사이킷런(Scikit-learn) 기초 (0) | 2019.05.22 |
| 머신러닝 프로젝트 실행 -5 (0) | 2017.05.15 |