파이썬으로 할 수 있는 일/파이썬 기초
데이터셋 그룹화-GroupBy (Pandas 레시피)
블루돌이
2019. 5. 12. 12:13
반응형
1. pandas 라이브러리를 읽어들입니다.
>>> import pandas as pd
2. 아래 주소에서 데이터셋을 읽어들이고, drinks라는 변수에 할당합니다.
>>> drinks = pd.read_csv('https://raw.githubusercontent.com/justmarkham/DAT8/master/data/drinks.csv')
>>> drinks.head() # drinks의 데이터셋의 구조를 알기 위해 상위 열(5)을 조회합니다.

3. 어느 대륙에서 평균보다 맥주를 더 많이 마시는가?
>>> drinks.groupby('continent').beer_servings.mean() # groupby를 사용해서, 대륙별 맥주 소비량 평균을 계산합니다

4. 각 대륙별 와인 소비 현황을 파악하려면 어떻게 해야 하는가?
>>> drinks.groupby('continent').wine_servings.describe() # describe를 사용해서 대륙별 전체 데이터 개수, 평균값, 표준편차, 최소값, 4분위수, 최대값을 보여줍니다

5. 각 대륙별 평균 알코올 소비량은 어떻게 되는가?
>>> drinks.groupby('continent').mean()
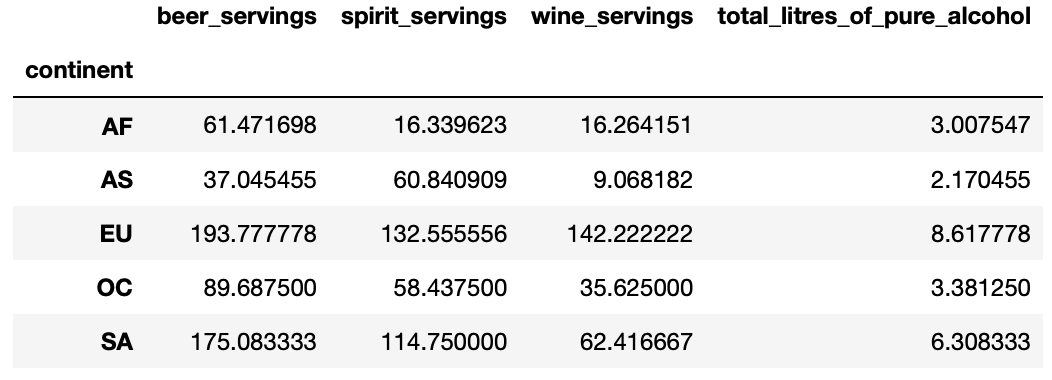
6. 각 대륙별 알코올 소비량 중앙값은 어떻게 되는가?
>>> drinks.groupby('continent').median()

7. 각 대륙별 와인 소비량의 평균값, 최소값, 최대값은 어떻게 되는가?
>>> drinks.groupby('continent').wine_servings.agg(['mean', 'min', 'max'])

(Source : Pandas exercises 깃헙)
반응형