Scikit-learn 라이브러리는 파이썬에서 가장 유명한 머신러닝 라이브러리 중 하나로, 분류(classification), 회귀(regression), 군집화(clustering), 의사결정 트리(decision tree) 등의 다양한 머신러닝 알고리즘을 적용할 수 있는 함수들을 제공합니다.
이번에는 머신러닝 수행 방법을 알아보기 전에, 다양한 샘플 데이터를 확보할 수 있는 방법들을 알아보려고 합니다.
데이터셋(Datasets) 얻기
머신러닝을 시작할 때, 간단하게 데이터셋을 얻어서 알고리즘을 테스트해 보는 것이 머신러닝을 이해하는데 있어 매우 유용합니다. 간단한 데이터셋으로 원리를 이해한 후, 실제 생활에서 얻을 수 있는 더 큰 데이터셋을 가지고 작업하는 것이 좋습니다.
우선 머신러닝을 연습하기 위해, 간단한 데이터셋을 얻을 수 있는 곳은 다음과 같습니다. 하나씩 차례대로 알아보도록 하겠습니다.
- 사이킷런의 빌트인 데이터셋
- 캐글(Kaggle) 데이터셋
- UCI(캘리포니아 대학, 얼바인) 머신러닝 저장소
<사이킷런 데이터셋 사용하기>
사이킷런에는 머신러닝을 쉽게 배울 수 있도록 하기 위해, 샘플 데이터셋을 가지고 있습니다.
샘플 데이터셋을 로드하기 위해, 데이터셋 모듈을 읽어들입니다. 다음은 Iris 데이터셋을 로드한 코드입니다.
>>> from sklearn import datasets
>>> iris = datasets.load_iris() # 아이리스 꽃 데이터셋 또는 피셔 아이리스 데이터셋은 영국의 통계 학자이자 생물학자인 로널드 피셔 (Ronald Fisher)가 소개한 다변수 데이터셋입니다. 데이터셋은 3종의 아이리스(Iris)로 된 50개 샘플로 구성되어 있습니다. 각 샘플로부터 4개의 피쳐(features:피쳐를 우리말로 변수 또는 요인이라고 표현하기도 함)를 측정할 수 있습니다: 꽃받침과 꽃잎의 길이와 너비입니다. 이러한 4가지 피쳐(features)의 결합을 바탕으로 피셔는 종을 서로 구분할 수 있는 선형 판별 모델을 개발했습니다.
로드된 데이터셋은 속성-스타일 접근을 제공하는 파이썬 딕셔너리, 번치(bunch) 객체로 표현됩니다.
>>> print(iris.DESCR) # DESCR 속성을 사용해 데이터셋의 정보를 다음과 같이 얻을 수 있습니다.

>>> print(iris.data) # data 속성을 사용해 피쳐를 알아볼 수 있습니다.

>>> print(iris.feature_names) # feature_names 속성으로 피쳐 이름을 알아낼 수 있습니다.

이것은 데이터셋이 꽃받침 길이, 꽃받침 너비, 꽃잎 길이, 꽃잎 너비 등 4개의 컬럼들로 구성되어 있다는 것을 의미합니다.

>>> print(iris.target) # 레이블을 알 수 있습니다.
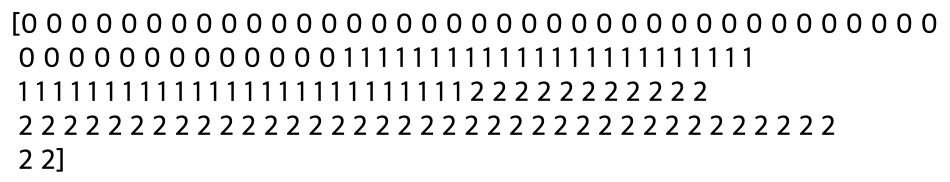
>>> print(iris.target_names) # 레이블 이름을 알 수 있습니다.

여기서 0은 'setosa'를, 1은 'versicolor'를 2는 'virginica'를 나타냅니다.
(사이킷런의 모든 샘플 데이터가 feature_names, target_names 속성을 지원하는 것은 아닙니다)
여기서, 데이터를 쉽게 다루기 위해, 판다스(Pandas)의 데이터프레임으로 변환하는 것이 유용합니다.
>>> import pandas as pd # pandas 라이브러리를 읽어들입니다.
>>> df = pd.DataFrame(iris.data)
>>> df.head()

<캐글(Kaggle) 데이터셋 사용하기>
데이터 과학자 및 머신러닝 학습자들에게 있어, 캐글(Kaggle)은 세계에서 가장 큰 커뮤니티입니다.
머신러닝 경쟁을 제공하는 플랫폼에서 시작하여, 현재 캐글(Kaggle)은 공개 데이터 플랫폼과 데이터 과학자를 위한 클라우드 기반 워크 벤치도 제공합니다.
구글이 2017년 3월에 캐글(Kaggle)을 인수했습니다.
우리는 머신러닝 학습자들을 위해, 캐글(Kaggle)에서 제공된 샘플 데이터셋을 이용할 수 있습니다.
몇가지 흥미로운 데이터셋이 있는데, 다음과 같습니다.
- 여성 신발 가격들 : 10,000개의 여성 신발 리스트와 그것들이 팔린 가격들(https://www.kaggle.com/datafiniti/womens-shoes-prices)
- 중국의 낙상 감지 데이터 : 노년 환자들의 활동과 의료 정보(https://www.kaggle.com/pitasr/falldata)
- 뉴욕시(NYC) 부동산 매매 : NYC 부동산 시장에서 1 년 동안 판매되는 부동산(https://www.kaggle.com/new-york-city/nyc-property-sales#nyc-rolling-sales.csv)
- 미국 비행 지연 : 2016년의 비행 지연(https://www.kaggle.com/niranjan0272/us-flight-delay)
<캘리포니아 대학, 어바인의 머신러닝 저장소 사용하기>
캘리포니아 대학, 어바인의 머신러닝 저장소는 머신러닝 알고리즘의 데이터 생성 경험적 분석을 위해, 머신러닝 커뮤니티에서 사용하는 데이터베이스, 도메인 이론 및 데이터 생성기 모음입니다.
이 거대한 데이터셋 모음 중에서 흥미로운 몇가지 데이터셋을 살펴보면 다음과 같습니다.
- 자동 MPG 데이터셋 : 다양한 유형의 자동차 연비에 관한 데이터 모음(https://archive.ics.uci.edu/ml/datasets/Auto+MPG)
- 학생 성과 데이터셋 : 중등 교육(고등학교)에서의 학생 성과 예상(https://archive.ics.uci.edu/ml/datasets/Student+Performance)
- 인구 조사 소득 데이터셋 : 인구조사 데이터를 기초로 소득이 년간 $ 50K를 초과하는지 예측(https://archive.ics.uci.edu/ml/datasets/census+income)
< 직접 자신의 데이터셋 생성하기>
실험을 위한 적당한 데이터셋을 찾을 수가 없다면, 직접 자신의 데이터셋을 생성합니다.
사이킷런(Scikit-learn) 라이브러리의 sklearn.datasets.samples_generator 모듈에는 다양한 유형의 문제에 대해 서로 다른 유형의 데이터 세트를 생성할 수 있는 많은 함수가 포함되어 있습니다.
다음과 같은 데이터셋들을 만들 수 있습니다.
- 선형으로 분산된 데이터셋
- 군집화된 데이터셋
- 순환 방식으로 분산되고 군집화된 데이터셋
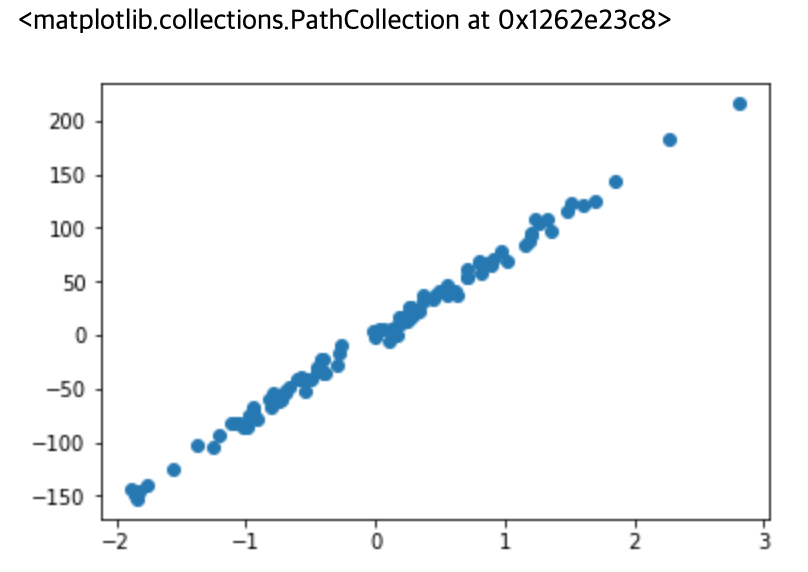
1. 선형으로 분산된 데이터셋
make_regression() 함수를 사용해 선형으로 분산된 데이타를 생성합니다. 아웃풋에 적용된 가우스 노이즈의 표준 편차뿐만 아니라, 원하는 피쳐의 수를 지정할 수도 있습니다.
>>> % matplolib inline
>>> import matplotlib.pyplot as plt
>>> from sklearn.datasets.samples_generator import make_regression
>>> X, y = make_regression(n_samples=100, n_features=1, noise=5.4)
>>> plt.scatter(X, y)
2. 군집화된 데이터셋
make_blobs()함수는 n개의 무작위 데이터 클러스터를 생성합니다. 이것은 비지도(자율)학습에서 군집화를 수행할 때 매우 유용합니다.
>>> %matplotlib inline
>>> import matplotlib.pyplot as plt
>>> import numpy as np
>>> from sklearn.datasets import make_blobs
>>> X, y = make_blobs(500, centers=3) # 군집화를 위한 등방성 가우시안 블롭 생성
>>> rgb = np.array(['r', 'g', 'b'])
>>> plt.scatter(X[:, 0], X[:, 1], color=rgb[y]) # 산포도와 컬러 코딩을 사용해 그립니다.

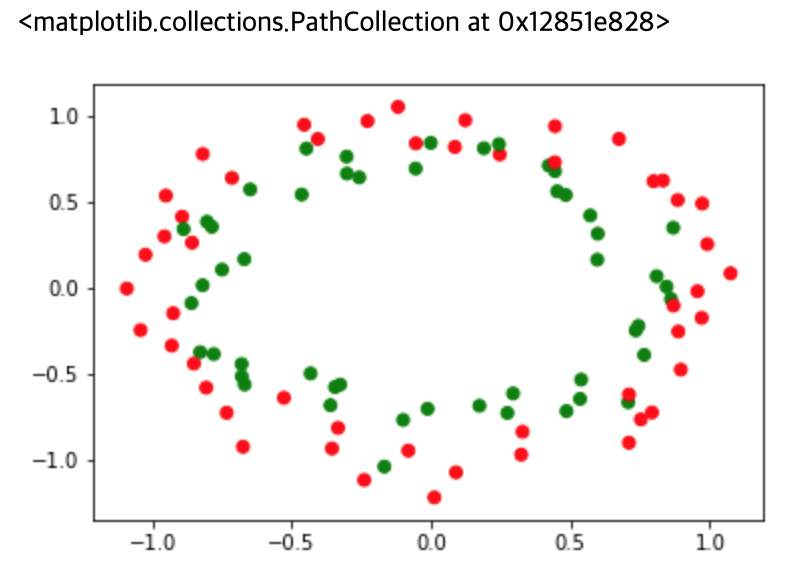
3. 순환 방식으로 분산되고 군집화된 데이터셋
make_circles()함수는 두 개의 차원에 작은 원을 포함하는 큰 원이 포함된 임의의 데이터셋을 생성합니다. SVM(
Support Vector Machines)과 같은 알고리즘을 사용하여 분류(classifications)를 수행할 때 유용합니다.
>>> %matplotlib inline
>>> import matplotlib.pyplot as plt
>>> import numpy as np
>>> from sklearn.datasets import make_circles
>>> X, y = make_circles(n_samples=100, noise=0.09)
>>> rgb = np.array(['r', 'g', 'b'])
>>> plt.scatter(X[:, 0], X[:, 1], color=rgb[y])
다음 번에는 간단한 선형 회귀(linear regression) 알고리즘을 구현해 보면서 사이킷런(Scikit-Learn) 기초 사용법을 익혀 보겠습니다.
(Source : Python Machine Learning, Wiley, 2019)
'파이썬으로 할 수 있는 일 > AI&머신러닝' 카테고리의 다른 글
| 데이터 정제(Data Cleaning)와 정규화(Normalizing) : 사이킷런(Scikit-learn) 기초 (0) | 2019.05.27 |
|---|---|
| 선형 회귀분석(Linear Regression) : 사이킷런(Scikit-learn) 기초 (0) | 2019.05.23 |
| 머신러닝 프로젝트 실행 -5 (0) | 2017.05.15 |
| 머신러닝 프로젝트 실행 -4 (0) | 2017.05.10 |
| 머신러닝 프로젝트 실행 -3 (0) | 2017.04.27 |


