 MCP로 구현하는 AI 개인비서: Claude와 구글 워크스페이스 통합으로 일상 업무 자동화하기
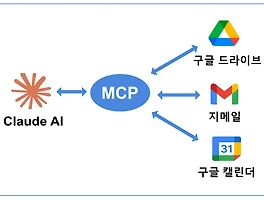
MCP로 업그레이드된 AI 에이전트를 어떻게 활용할 수 있을까에 대해 최근에 많이 생각해 보고 있다. 옵시디언과 연결해서 내가 쓰는 어떤 글이든, 태그를 생성해 주고 서로 연결할 주요 키워드를 찾아 서로 연결해주는 것도 좋은 활용 방법이라고 생각한다. 가장 많이 활용하는 MCP는 웹 검색을 하는 다양한 MCP들(brave, exa, firecrawl, naver api 등)이었다. 그 다음에 내 로컬 파일시스템 접근하는 MCP가 있었고, 구글 드라이브, 캘린더, 지메일 등에 접속하는 MCP가 있었다.구글 드라이브, 캘린더, 지메일에 접속하는 기능이 기본적으로 추가되었는줄 알았는데, 읽어들이는 기능만 추가되었고 아직 제대로 기능하지 않는 것 같다. 언젠가는 읽고 쓰는 기능을 쉽게 쓸 수 있게 되겠지만, 기..
MCP로 구현하는 AI 개인비서: Claude와 구글 워크스페이스 통합으로 일상 업무 자동화하기
MCP로 업그레이드된 AI 에이전트를 어떻게 활용할 수 있을까에 대해 최근에 많이 생각해 보고 있다. 옵시디언과 연결해서 내가 쓰는 어떤 글이든, 태그를 생성해 주고 서로 연결할 주요 키워드를 찾아 서로 연결해주는 것도 좋은 활용 방법이라고 생각한다. 가장 많이 활용하는 MCP는 웹 검색을 하는 다양한 MCP들(brave, exa, firecrawl, naver api 등)이었다. 그 다음에 내 로컬 파일시스템 접근하는 MCP가 있었고, 구글 드라이브, 캘린더, 지메일 등에 접속하는 MCP가 있었다.구글 드라이브, 캘린더, 지메일에 접속하는 기능이 기본적으로 추가되었는줄 알았는데, 읽어들이는 기능만 추가되었고 아직 제대로 기능하지 않는 것 같다. 언젠가는 읽고 쓰는 기능을 쉽게 쓸 수 있게 되겠지만, 기..







