"이번 트렌드 분석을 위해 네이버 블로그에서 데이터를 수집해야 하는데... 코딩은 잘 모르는데 어떻게 하지?" 🤔
이런 고민, 한 번쯤 해보셨을 것이다.
특히 네이버 블로그처럼 자바스크립트로 구현된 사이트에서 데이터를 수집하는 것은 전문 개발자에게도 까다로운 작업이다.
하지만 오늘 소개해 드릴 방법을 알게 된다면, 코드 한 줄 없이도 웹사이트의 데이터를 몇 분 만에 수집할 수 있게 될 거라고 말할 수 있다(난 이틀을 n8n과 Crawl4AI로 헤매었지만 말이다).
얼마 전, 마케팅 구상을 위해 네이버 블로그의 특정 키워드 관련 포스팅 100개 정도를 분석하려고 했다. Python으로 하나씩 가져오는 것은 가능했지만, 내가 하고 싶은 것은 주기적으로 데이터를 가져와서 분석한 후 나에게 인사이트를 주는 자동화였다. 그래서, 여러 가지 스크래핑 자동화에 대해 검색을 하다가 발견한 것이 바로 **n8n(엔에이트엔)**과 Crawl4AI의 환상적인 조합이었다.
n8n과 Crawl4AI: 노코드 스크래핑의 완벽한 파트너십
n8n은 Zapier나 Make(구 Integromat)와 같은 워크플로우 자동화 툴이지만, 오픈소스이며 셀프 호스팅이 가능하다는 큰 장점이 있고 기본적인 내용은 이미 살펴보았다. 내 컴퓨터나 서버에 직접 설치해서 무료로 사용할 수 있기 때문에 추가로 지출이 안든다.
Crawl4AI는 완전 오픈소스 웹 스크래퍼로, 헤드리스 브라우저를 사용해 자바스크립트가 렌더링된 웹사이트도 완벽하게 스크래핑할 수 있다고 한다. 게다가 Docker를 통해 API 형태로 사용할 수 있어 n8n과 쉽게 통합할 수 있다는 유튜브 영상도 있다.
이 두 도구의 조합이 주는 강력한 장점:
- 자바스크립트 렌더링 페이지도 완벽 스크래핑 - 네이버 블로그처럼 동적 콘텐츠도 문제없음
- 단 3개의 노드만으로 완성 - 복잡한 설정 필요 없이 간단하게 구축
- 완전 무료 & 오픈소스 - 클라우드 호스팅 비용 외에 추가 비용 없음
- 자동화 가능 - 정기적인 데이터 수집을 스케줄링 할 수 있음
n8n 설치하기
n8n을 설치하는 방법은 여러 가지가 있지만, 가장 간단한 방법은 Docker를 이용하는 것이다.
저번에도 얘기했지만, N100과 같은 저전력 미니PC에서도 충분히 돌아갈 정도로 가볍다. 나도 N100 미니PC를 24시간 켜놓고, 그 위에 n8n을 돌려놓고 있고, 외부 접속은 Chrome 원격 데스크탑을 통해 하고 있다.
version: "3"
services:
n8n:
image: n8nio/n8n:latest
ports:
- "5678:5678"
environment:
- N8N_BASIC_AUTH_ACTIVE=true
- N8N_BASIC_AUTH_USER=원하는_사용자명
- N8N_BASIC_AUTH_PASSWORD=원하는_비밀번호
volumes:
- ~/.n8n:/home/node/.n8n이 코드를 docker-compose.yml 파일로 저장하고, 터미널에서 docker-compose up -d 명령어만 실행하면 끝! 웹 브라우저에서 http://localhost:5678으로 접속하면 n8n 대시보드를 만날 수 있다.
Docker가 부담스럽다면 나처럼 Node.js 환경에서 npm install n8n -g 명령어로 직접 설치할 수도 있다.
Crawl4AI 설치하기
Crawl4AI는 반드시 Docker를 통해 설치해야 한다.
Crawl4AI는 내부적으로 헤드리스 브라우저를 사용하기 때문에 CPU와 RAM을 많이 사용할 수 있음도 알아두자. 가장 간단한 설치 방법은 다음과 같다:
# Crawl4AI Docker 이미지 받기
docker pull unclecode/crawl4ai:basic-amd64
# 컨테이너 실행하기 (보안을 위한 API 토큰 설정)
docker run -p 11235:11235 -e CRAWL4AI_API_TOKEN=나만의_비밀토큰 unclecode/crawl4ai:latest이제 http://localhost:11235에서 Crawl4AI API가 실행된다! 간단하죠?
그런데, 난 미니PC에서 돌리기 때문에 너무 무거운 작업을 돌리기는 어렵다. 그래서, Docker가 돌고 있는 Synology NAS에 Crawl4AI를 설치하기로 했다.
localhost로 돌리면 네트워크 걱정이 없기 때문에 바로 된다고 한다.
그런데, 난 NAS에 Crawl4AI를 돌리고 미니PC에 구동되고 있는 n8n에서 Crawl4AI를 접속해서 작업을 처리해야 한다. 여기서 이틀을 헤매었다. 포기할까 하다가 Cursor에게 이것저것 물어보면서 해결했다.
처음에 부딪친 장벽은 Port문제였다. NAS 외부에서 접속하려면 Port가 열려 있어야 하는데, 방화벽 등으로 막혀 있을 수 있어 그걸 알아봐야 했다. 그리고, API를 설정하고 토큰을 통해 입장하도록 해야만 하는지 알아봐야했다. 여러번의 삽질을 통해 Port 설정도 해결하고, 일단 내부망에서만 사용하기 때문에 API설정 없이 그냥 접속할 수 있도록 조치했다.
미니 PC 브라우저에서 Crawl4AI를 열어보았다. 이걸로 NAS 외부에서 접속이 가능한 것을 확인했다.

네이버 블로그 스크래핑 전 고려사항
본격적으로 스크래핑을 시작하기 전에 몇 가지 중요한 점을 확인해야 한다:
- 웹사이트 정책 확인: 네이버의 robots.txt 파일(https://blog.naver.com/robots.txt)을 확인하고 스크래핑 허용 범위를 파악해야 한다.
- 적절한 속도 제한: 과도한 요청으로 서버에 부담을 주지 않도록 적절한 딜레이를 설정하자.
- 개인정보 주의: 블로그 작성자의 개인정보를 수집하거나 무단으로 사용하지 말자.
- 목적 제한: 수집한 데이터는 개인 연구나 분석 목적으로만 사용하는 것이 좋다.
많은 사이트들이 robots.txt 파일을 통해 크롤링 정책을 명시하고 있으니, 이를 꼭 확인하고 존중하는 것이 중요하다!
실전: n8n + Crawl4AI로 네이버 블로그 스크래핑 워크플로우 만들기
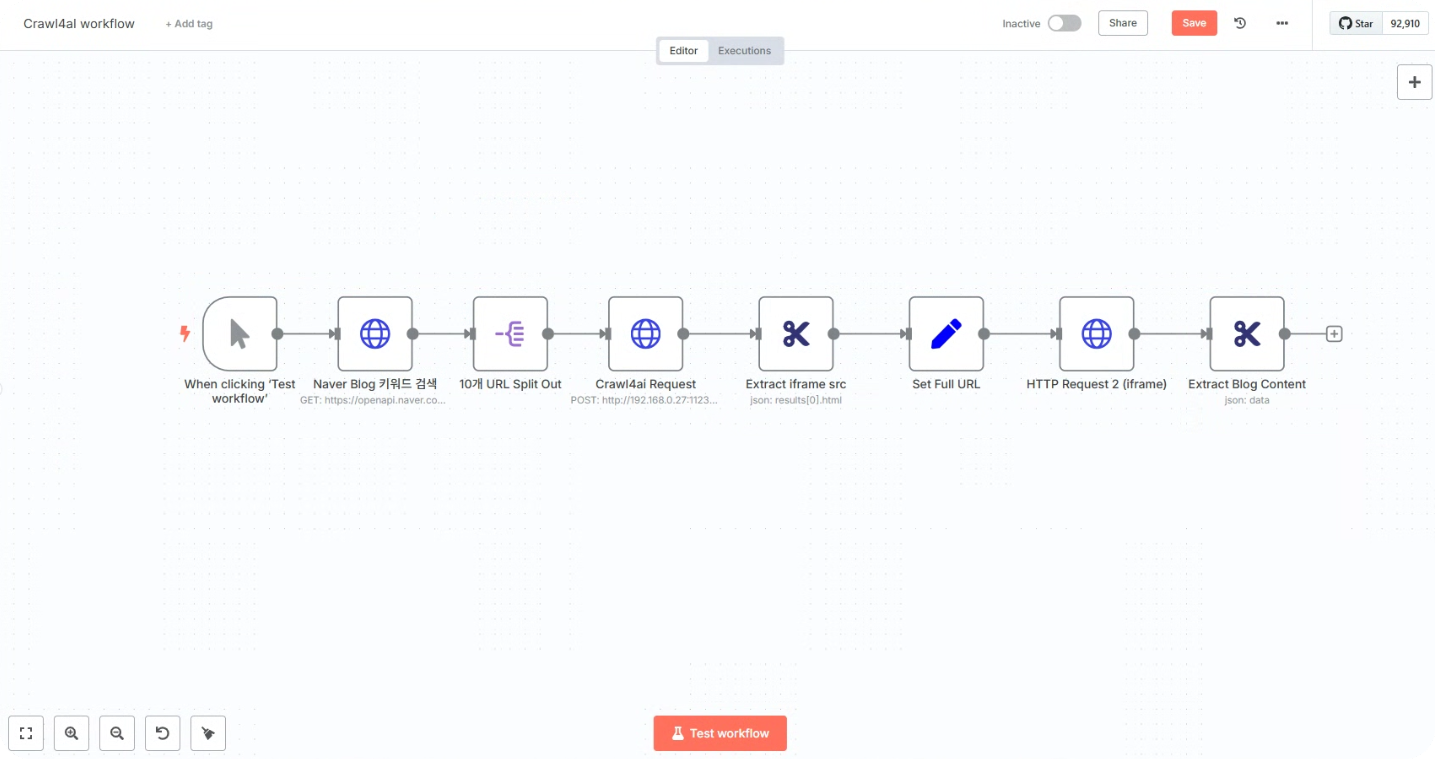
이제 실제로 워크플로우를 만들어 보자! 단 8개의 노드만(많기도 하다)으로 완벽한 스크래핑 워크플로우를 구축할 수 있다.
1단계: 새 워크플로우 생성
n8n 대시보드에서 "Create Workflow" 버튼을 클릭하고, 적당한 이름(예: "Crawl4ai workflow")을 지정했다.
2단계: Manual Trigger 노드 추가
가장 간단하게는 "Manual Trigger" 노드를 선택한다. 이렇게 하면 버튼 클릭 한 번으로 워크플로우를 실행할 수 있다. 나중에 자동화가 필요하다면 "Schedule Trigger"(시간 기반)를 선택하도록 할 것이다.
3단계: HTTP Request 노드 설정 (네이버 개발자센터에서 발급받은 API 사용)
내가 하고 싶은 것은 알고 싶은 '키워드'를 입력해서 키워드 관련한 최신 네이버 블로그를 찾고 관련 인사이트를 얻는 것이다. 그래서, 일단 네이버 개발자센터에서 발급받은 API를 통해 키워드 관련한 최신 네이버 블로그 10개를 추출하도록 하였다.
- "+" 버튼을 클릭하고 "HTTP Request" 노드를 추가한다.
- 다음과 같이 설정한다:
- Method: GET
- URL: https://openapi.naver.com/v1/search/blog.json
- Headers:
- X-Naver-Client-Id: 자신의 Naver Client ID 입력
- X-Naver-Client-Secret: 자신의 Client Secret 입력
- Query Parameters를 Send로 활성화
- Specify Query Parameters : Using Fields Below
- Query Parameters
- Name을 query로 하고 Value에 '키워드'입력
- 최신 블로그를 찾기 위해 하나 더 추가해서 Name은 sort로 하고 Value는 date로 설정

나중에 자동화를 진행할 때는 query의 Value를 구글 시트 등에서 매일 일정한 시간에 받아오도록 설정하면 된다.
4단계: Split 노드 추가
위 결과로 10개의 블로그 관련 정보가 넘어온다. URL과 Content라고 되어 있는 부분이 보여서, 이러면 굳이 스크래핑을 하지 않아도 되겠다 싶었다. 그런데, 실제 블로그의 Content는 바로 넘어오지 않았다.
5단계: Crawl4AI 노드 추가
4단계 Split노드에서 URL을 받아 Crawl4AI에게 보내는 HTTP Request노드를 만들었다.
처음에는 Port도 맞추고 했는데도 불구하고, 아예 Crawl4AI에 접속하지 못하는 것처럼 보였다.
크롬 브라우저에서 playground로는 접속이 되서 크롤링이 되는 것을 확인했으니, port가 Nas 외부로 열린것은 확인이 된 것이라, 설정 파라미터가 잘못되어서 접속에 문제가 있는 것은 아닌지 다시 한번 파악해 보았다.
결국 다음과 같은 세팅으로 접속과 정상 동작을 확인하였다.
- Method : POST
- URL : http://My NAS IP(이건 각자 NAS IP):11235/crawl (여기 Port 11235는 동일하게 설정하던지 각자 변경해서 사용하면 된다)
- Send Headers 설정
네이버 블로그는 스크래핑을 하는 것을 차단하기 때문에,
Header Parameters를 5가지 정도는 입력해야 블로그 글을 가져올 수 있다고 한다(이건 Cursor에게 물어보고 답을 받은 거라 다 필요한지는 모르겠음).
- Specify Headers : Using Fields Below
- Header Parameters
| Name | Value |
| Content-Type | application/json |
| User-Agent | Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/124.0.0.0 Safari/537.36 |
| Accept | text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,*/*;q=0.8 |
| Accept-Language | ko-KR,ko;q=0.9,en-US;q=0.8,en;q=0.7 |
| Referer | https://blog.naver.com/ |

6단계: Extract iframe src 노드 추가
이건 스크래핑한 Content에서 블로그 글이 들어있는 iframe src의 주소를 가져오기 위한 노드이다.
이건 Cursor에게 위에 만든 스크래핑한 부분에 블로그 글이 안보인다고 했더니, 네이버 블로그 글은 내부 iframe src에 들어가 있어서 위에서 스크래핑한 것을 통해 블로그 글의 URL을 받아오고 그걸 통해 블로그 글만 다시 스크래핑해야 한다고 말했다.
그래서, 받은 내용을 Cursor에게 보여주고 블로그 글 URL을 받아올 수 있는 노드를 만들어 달라고 했다.
JSON Property가 처음에는 data로 되어 있어서, 결과 값을 못가져 왔는데, 다시 수정해 달라고 하니, results[0].html을 넣으라고 해서 그렇게 했다.

7단계: Set Full URL 노드 추가
이건 다시 블로그 글만 스크래핑하기 위해 전체 Full URL을 설정하는 노드이다.
Value를 https://blog.naver.com{{$json["iframeSrc}"]}}로 해서, https이하의 주소와 6단계 노드에서 만들어진 값을 하나로 합쳤다.

8단계: iframe 내부의 글 내용 가져오는 노드 추가
이건 다시 블로그 글만 가져오는 HTTP Request 노드이다.
GET을 사용해서 앞에서 만들어진 fullUrl에 있는 Contents를 가져오면 마무리된다.
이렇게 되면, 블로그 글 스크래핑은 마무리된다.
여기서 원하는 정보를 추출하도록 하거나, LLM을 접목해서 요약 정리하도록 하고 그 결과를 받아보는 것도 괜찮을 것 같다.

윤리적 스크래핑과 법적 고려사항
웹 스크래핑은 강력한 도구이지만, 책임감 있게 사용해야 한다:
- 이용약관 준수: 네이버의 서비스 이용약관을 확인하고 스크래핑이 허용되는지 확인
- robots.txt 존중: 웹사이트의 robots.txt 파일에서 허용되는 범위 확인
- 정당한 목적: 연구, 개인 학습 등 합법적인 목적으로만 사용
- 과도한 요청 자제: 서버에 부담을 주지 않도록 요청 빈도 제한
- 데이터 보호: 수집한 개인정보를 적절히 보호하고 프라이버시 존중
마무리: 노코드 스크래핑의 무한한 가능성
이 방법은 네이버 블로그뿐만 아니라 다양한 웹사이트에 적용할 수 있을 것이다:
- 쇼핑몰 제품 정보 및 가격 모니터링
- 뉴스 사이트의 특정 키워드 관련 기사 알림
- 부동산 매물 정보 자동 수집
- 경쟁사 웹사이트 업데이트 추적
- 소셜 미디어 콘텐츠 트렌드 분석
데이터는 현대 비즈니스의 핵심 자산이다.
n8n과 Crawl4AI를 통해 여러분도 이제 개발자 없이 웹 데이터의 바다에서 필요한 정보를 쉽게, 그리고 효율적으로 수집할 수 있게 되었다.
오늘은 여기까지 하고, 다음에 위 워크플로우를 자동화해서 내가 원하는 결과를 뽑아내는 것까지 진행해 보도록 하겠다. 기대해 주시길! 😊 여기까지도 매우 힘든 하루였다.
'파이썬으로 할 수 있는 일 > 크롤링' 카테고리의 다른 글
| 최근의 웹 스크래핑에 대해 (0) | 2023.10.20 |
|---|---|
| Scrapy(스크래피)란? (0) | 2017.03.23 |
