파이썬의 pandas는 이제 필수적으로 알아야 하는 라이브러리가 되었다고 생각한다. 금융 쪽 뿐만 아니라 웹 스크래핑을 통해 데이터를 확보하고 그 자료를 딥러닝 등으로 분석하기 전 전처리에 유용하게 사용할 수 있는 도구로써도 유용하다고 본다.
우선적으로 Pandas DataFrame에서 사용할 수 있는 가장 기본적인 기능에 대해서 정리해 보고자 한다.
이번 글에서는 DataFrame에서 각 열과 컬럼(행)의 이름을 변경하는 것부터 해보자.
>>> import pandas as pd # pandas 라이브러리를 읽어들인다
>>> movies = pd.read_csv('movie.csv', index_col = 'movie_title') # csv파일을 읽어들이면서, 컬럼 중에서 인덱스로 만들 컬럼을 선택한다.
아래와 같이 딕셔너리로 된 대체 인덱스 및 컬럼으로 대입할 변수를 만듭니다.
>>> idx_rename = {'Avatar' : 'Ratava', 'Spectre' : 'Ertceps'}
>>> col_rename = {'director_name' : 'Director Name', 'num_critic_for_reviews' : 'Critical Reviews'}
rename 메서드를 사용해서, 인덱스와 컬럼에 딕셔너리를 전달합니다.
>>> movie_rename = movie.rename(index=idx_rename, columns=col_rename)
>>> movie_rename.head() # DataFrame 형태의 변수에 담긴 상위 열 데이터 일부(5개)를 조회합니다.
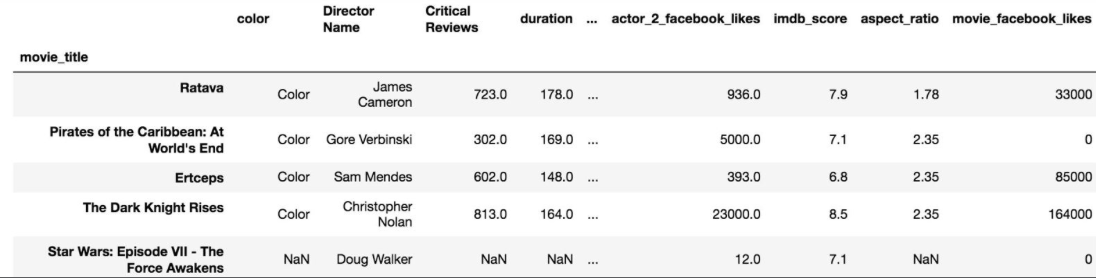
(Source : Pandas Cookbook 깃헙)
앞으로도 짧게 파이썬 관련 유용한 정보를 정리해 보려고 합니다.
'파이썬으로 할 수 있는 일 > 파이썬 기초' 카테고리의 다른 글
| 데이터셋 그룹화-GroupBy (Pandas 레시피) (0) | 2019.05.12 |
|---|---|
| 데이터 필터링 및 정렬(Pandas 레시피) (0) | 2019.05.11 |
| 파이썬으로 데이터 분석에 도전해 보자 (0) | 2019.01.31 |
| Pandas의 index에 대해 (0) | 2018.11.30 |
| Pandas DataFrame (0) | 2018.11.28 |


