퀀트Quant 투자를 달리 표현하면 데이터 기반 data-driven 전략이라고 할 수 있다.
퀀트는 정량적 방법론을 기반으로 투자 의사를 결정하는 것이며, 정량적 방법론이란 모든 것을 수치화하는 것을 의미한다.
사용하는 데이터에 따라 주가를 사용해 기술 지표를 만들고 이를 투자에 활용하는 '기술 지표 투자 전략'과 기업 재무제표를 사용하는 '가치 투자 전략', 이렇게 두 가지로 크게 나눌 수 있다.
주식 시장을 바라보는 트레이더의 시각에 따라 사용되는 지표는 다르다.
기술 지표를 활용한 퀀트 투자 전략 구현에서의 관건은 주가 데이터를 활용해 기술 지표를 만드는 것이다.
많은 파이썬 라이브러리에서 해당 기능을 제공하지만, 전략 확장성을 위해 수식을 기반으로 직접 만들어보는 것이 더 의미가 있다.
해당 지표들로 신호를 발생시켜 종목을 매매하고 전략의 수익률이나 승률 등을 살펴보는 방법도 알아본다.
기술 지표를 활용한 퀀트 투자 방법으로 모멘텀 전략과 평균 회귀 전략을 알아볼 것이다. 평균 회귀와 모멘텀은 서로 상반된 개념이다. 두 전략의 상관관계가 낮고 전략이 초점을 맞추는 시간대도 다르기 때문에 양극에 있는 두 방법을 살펴볼 가치는 충분하다고 볼 수 있다.
가치 투자 전략은 당기순이익, 영업이익, 영업이익률, 매출액, 부채비율, PER, PBR, PSR, PCR, ROE, ROA 등 기업의 가치 판단에 기준이 되는 재무제표 데이터를 기초로 한다.
가치 투자 전략에서는 기준이 되는 데이터에서 순위를 매겨 분위별로 자르는 작업이 훨씬 더 중요하다.
하지만 전략 평가는 기술 지표를 활용한 퀀트 투자 방법과 유사하다.
평균 회귀 전략
평균 회귀 (regression to mean)란 결과를 예측할 때 평균에 가까워지려는 경향성을 말한다. 한번 평균보다 큰 값이 나오면 다음번에는 평균보다 작은 값이 나와 전체적으로는 평균 수준을 유지한다는 의미다.
주식시장에서도 평균 회귀 현상이 통용되는지 검증하려는 많은 시도가 있었다.
이 현상에 의하면, 가격이 평균보다 높아지면 다음번에는 평균보다 낮아질 확률이 높다.
평균 회귀 속성을 이용한 전략을 들여다보면, 주가의 평균가격을 계산해 일정 범위를 유지하느냐 이탈하느냐에 따라 매매를 결정한다. 현재 주가가 평균가격보다 낮으면 앞으로 주가가 상승할 것으로 기대해 주식을 매수하고, 현재 주가가 평균가격보다 높으면 앞으로 주가가 하락할 것으로 예상해 주식을 매도하는 규칙을 설정할 수 있다.
볼린저 밴드 Bollinger band
볼린저 밴드는 현재 주가가 상대적으로 높은지 낮은지를 판단할 때 사용하는 보조지표다. 볼린저 밴드는 3개 선으로 구성되는데, 중심선은 이동평균 moving average 선, 상단선과 하단성을 구성하는 표준편차 standard deviation 밴드다.
볼린저 밴드를 사용하는 이유는 이동 평균선으로 추세를 관찰하고 상단선과 하단선으로 밴드 내에서 현재 가격의 상승과 하락폭을 정량적으로 계산할 수 있기 때문이다. 볼린저 밴드는 '추세'와 '변동성'을 분석해주어 기술 분석에서 활용도가 높으며 평균 회귀 현상을 관찰하는 데도 매우 유용하다.
보통 중심선을 이루는 이동 평균선을 계산할 땐 20일을 사용하고 상하위 밴드는 20일 이동 평균선 ± 2 * 20일 이동 표준 편차(σ)를 사용한다.
그럼 판다스를 사용해 볼린저 밴드 공식을 구현해 보도록 한다.
import pandas as pd
import FinanceDataReader as fdr
df = fdr.DataReader('AAPL', '1997-01-01', '2023-09-12') #애플 주식데이터를 가져온다.
df.head()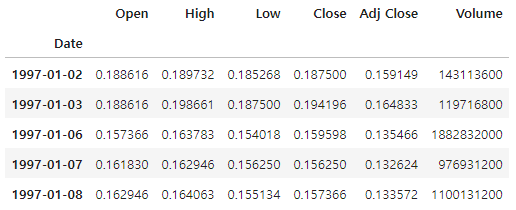
가장 먼저 해야할 작업은 데이터를 불러와 탐색해 보는 것이다.
애플('AAPL') 데이터를 실시간으로 불러와 df 변수에 저장한 후 head()함수를 통해 상위 5개 데이터를 확인한다.
인덱스는 날짜(Date)로 되어 있고, 각 컬럼은 시가(Open), 고가(High), 저가(Low), 종가(Close), 수정 종가(Adj Close), 거래량(Volume) 데이터로 구성된다.
데이터프레임에 있는 describe() 함수를 사용해 데이터셋의 분포, 경향 분산 및 형태를 요약하는 정보를 확인할 수 있다.
df.describe()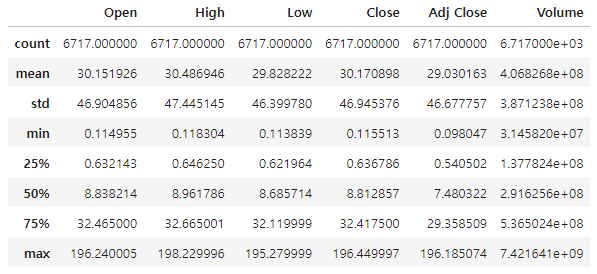
위 데이터셋에서 볼린저 밴드 분석에 필요한 컬럼만 선택하도록 한다.
price_df = df.loc[:, [''Adj Close']].copy()
price_df.head()
price_df 데이터셋으로 볼린저 밴드를 만들어 본자.
- 상단 밴드 = 중간 밴드 + 2*20일 이동 표준 편차
- 중간 밴드 = 20일 이동 평균선
- 하단 밴드 = 중간 밴드 - 2*20일 이동 표준 편차
먼저 중간 밴드를 만들도록 한다. 중간 밴드의 20일 이동 평균선은 판다스의 rolling() 함수를 이용하여 만든다.
price_df['center'] = price_df['Adj Close'].rolling(window = 20).mean()
price_df.iloc[18:25]
iloc 인덱서를 사용해 18행부터 24행까지 어떤 값이 들어있는지 확인해 본다. 새롭게 만들어진 center 컬럼은 rolling()함수와 mean()함수로 계산된 20일 이동 평균선을 의미한다.
rolling() 함수 특성상 window 입력값으로 20일을 주었기 때문에 데이터가 20개 미만인 부분은 결측치를 의미하는 NaN으로 표시된다.
일반적으로 결측치는 어쩔 수 없이 생성되기 때문에 볼린저 밴드에 필요한 기간보다 앞뒤로 더 많은 데이터(보통 쿠션 데이터 cushion data라고 부르는 여분의 데이터)를 추가하여 분석을 해야 한다. 실무에서는 생성하려는 자료를 고려해서 작성하는 것이 중요하지만, 여기서는 결측치가 발생한 행을 삭제한다.
중간 밴드를 만들었으니 이번에는 상단 밴드와 하단 밴드를 만든다.
price_df['ub'] = price_df['center] + 2 * price_df['Adj Close'].rolling(window=20).std()
price_df.iloc[18:25]상단 밴드는 'ub'라는 컬럼으로 만들고, 표준 편차를 계산하는 std() 함수로 이동 표준 편차를 구한다.
price_df['db'] = price_df['center'] - 2 * price_df['Adj Close'].rolling(window=20).std()
price_df.iloc[18:25]
볼린저 밴드는 다음에 재활용할 수 있도록 파이썬 함수로 만들어 저장하면 편리하게 사용할 수 있다.
n = 20
sigma = 2
def bollinger_band(price_df, n, sigma):
bb = price_df.copy()
bb['center'] = price_df['Adj Close'].rolling(n).mean() # 중앙 이동 평균선
bb['ub'] = bb['center'] + sigma * price_df['Adj Close'].rolling(n).std() # 상단밴드
bb['db'] = bb['center'] - sigma * price_df['Adj Close'].rolling(n).std() # 하단밴드
return bb
bollinger = bollinger_band(price_df, n, sigma)그 다음 기간을 나눠 볼린저 밴드를 활용한 전략의 성과를 확인해 보자.
base_date = '2008-01-02'
sample = bollinger.loc[base_date:]
sample.head()
base_date 변수에 새로운 날짜를 할당하고 설정된 날짜 이후 데이터로 전략 성과를 확인한다.
평균 회귀 전략에서 진입/청산 신호가 발생할 대 우리가 취하는 행동을 기록할 데이터프레임을 만들어보자. 앞으로 이러한 데이터프레임을 trading book이라고 명명한다.
다음 book 변수를 만들어 거래내역 컬럼을 만든다.
book = sample[['Adj Close']].copy()
book['trade'] = '' # 거래내역 컬럼
book.head()
위 코드를 함수화 하면 다음과 같다.
def create_trade_book(sample):
book = sample[['Adj Close']].copy()
book['trade'] = ''
return(book)이번에는 볼린저 밴드를 활용한 전략 알고리즘을 만들어 본다.
트레이딩 전략 알고리즘에 대한 전체 코드는 다음과 같다.
def tradings(sample, book):
for i in sample.index:
if sample.loc[i, 'Adj Close'] > sample.loc[i, 'ub']: # 상단밴드 이탈시 동작 안함
book.loc[i, 'trade'] = ''
elif sample.loc[i, 'db'] > sample.loc[i, 'Adj Close']: # 하단밴드 이탈시 매수
if book.shift(1).loc[i, 'trade'] == 'buy': # 이미 매수 상태라면
book.loc[i, 'trade'] = 'buy' # 매수상태 유지
else:
book.loc[i, 'trade'] = 'buy'
elif sample.loc[i, 'ub'] >= sample.loc[i, 'Adj Close'] and sample.loc[i, 'Adj Close'] >= sample.loc[i, 'db']: # 볼린저밴드 안에 있을 시
if book.shift(1).loc[i, 'trade'] == 'buy':
book.loc[i, 'trade'] = 'buy' # 매수상태 유지
else:
book.loc[i, 'trade'] = '' # 동작 안함
return (book)이 전략의 특징은 장기 보유보다는 과매도 / 과매수 구간을 포착하는 단기 매매에 더 효과적이라고 해석한다.
완성된 거래 전략을 수행하면 다음과 같이 거래내역이 기록된 것을 확인할 수 있다.
book = tradings(sample, book)
book.tail(10)
다음은 트레이딩 book에 적혀있는 거래내역대로 진입/청산 일자에 따른 매수/매도 금액을 바탕으로 수익률을 계산해 보자.
def returns(book): # 손익계산
rtn = 1.000
book['return'] = 1
buy = 0.0
sell = 0.0
for i in book.index:
# long 진입
if book.loc[i, 'trade'] == 'buy' and book.shift(1).loc[i, 'trade'] == '':
buy = book.loc[i, 'Adj Close']
print('진입일 : ', i, 'long 진입가격 : ', buy)
#long 청산
elif book.loc[i, 'trade'] == '' and book.shift(1).loc[i, 'trade'] == 'buy':
sell = book.loc[i, 'Adj Close']
rtn = (sell-buy) / buy + 1 # 손익 계산
book.loc[i, 'return'] = rtn
print('청산일 : ', i, 'long 진입가격 : ', buy, '| long 청산가격 : ', sell, '| return:', round(rtn,4))
if book.loc[i, 'trade'] == '' : # 제로 포지션
buy = 0.0
sell = 0.0
acc_rtn = 1.0
for i in book.index:
rtn = book.loc[i, 'return']
acc_rtn = acc_rtn * rtn # 누적 수익률 계산
book.loc[i, 'acc return'] = acc_rtn
print('Accumulated return : ', round(acc_rtn, 4))
return (round(acc_rtn, 4))수익률을 저장한 변수와 book변수에 수익률 컬럼을 만든다.
for-loop문을 돌면서 포지션 여부에 따라 수익률을 계산해 데이터프레임에 저장하고, 최종적으로 누적 수익률을 계산한다.
print(returns(book))
변화 추이를 한눈에 보고 싶다면 누적 수익률을 그래프로 그려보자.
import matplotlib.pylab as plt
book['acc return'].plot()
백테스팅이라는 불리는 과정을 통해 실제 데이터를 가지고 확인을 해봐야 자신이 만든 전략의 신뢰도를 높일 수 있다. 여기서는 간단하게 과거 데이터를 통해 평균 회귀 전략에 대한 기본 개념을 정리해 본 것이다. 따라서, 이 전략을 바로 활용하기는 어렵다고 생각한다. 또한 평균 회귀 전략이 모든 종목에 적합한 것도 아니다.
그렇기 때문에 본인의 투자 철학과 해당 주식에 대한 면밀한 파악을 통해 전략을 수립하고 실행하도록 해야 한다.
'파이썬으로 할 수 있는 일 > 실사용' 카테고리의 다른 글
| 파이썬으로 연습해보는 퀀트 투자 - 듀얼 모멘텀 중 상대 모멘텀 전략 (0) | 2023.09.19 |
|---|---|
| 파이썬으로 연습해보는 퀀트 투자 - 듀얼 모멘텀 중 절대 모멘텀 전략 (0) | 2023.09.13 |
| 주피터 노트북(Jupyter Notebook) 서버 접속 및 실행 (0) | 2023.09.01 |
| Python WMS(Workflow Management System) 도구들 (1) | 2022.04.08 |
| 네이버 스마트스토어 API 활용 기초 (0) | 2020.04.24 |



