
반응형
1. pandas 라이브러리를 읽어들입니다.
>>> import pandas as pd
2. 다음 데이터로 3개의 딕셔너리 데이터셋을 만듭니다.
>>> raw_data_1 = { 'subject_id' : ['1', '2', '3', '4', '5'], 'first_name' : ['Alex', 'Amy', 'Allen', 'Alice', 'Ayoung'], 'last_name' : ['Anderson', 'Ackerman', 'Ali', 'Aoni', 'Atiches']}
>>> raw_data_2 = {'subject_id' : ['4', '5', '6', '7', '8'], 'first_name' : ['Billy', 'Brian', 'Bran', 'Bryce', 'Betty'], 'last_name' : ['Bonder', 'Black', 'Balwner', 'Brice', 'Btisan']}
>>> raw_data_3 = {'subject_id' : ['1', '2', '3', '4', '5', '7', '8', '9', '10', '11'], 'test_id' : [51, 15, 61, 16, 14, 15, 1, 61, 16]}
3. data1, data2, data3라는 변수에 각각 할당합니다.
>>> data1 = pd.DataFrame(raw_data_1, columns = ['subject_id', 'first_name', 'last_name'])
>>> data2 = pd.DataFrame(raw_data_2, columns = ['subject_id', 'first_name', 'last_name'])
>>> data3 = pd.DataFrame(raw_data_3, columns = ['subject_id', 'test_id'])
4. 행을 따라 두 개의 dataframe을 결합하고 all_data 변수에 할당합니다.
>>> all_data = pd.concat([data1, data2])
>>> all_data

5. 컬럼에 따라 두개의 dataframe을 결합하고 all_data_col 변수에 할당합니다.
>>> all_data_col = pd.concat([data1, data2], axis = 1)
>>> all_data_col

6. data3을 출력합니다.
>>> data3

7. subject_id 값을 통해 all_data와 data3를 병합합니다.
>>> pd.merge(all_data, data3, on='subject_id') # on 인수를 통해 기준열을 명시했습니다
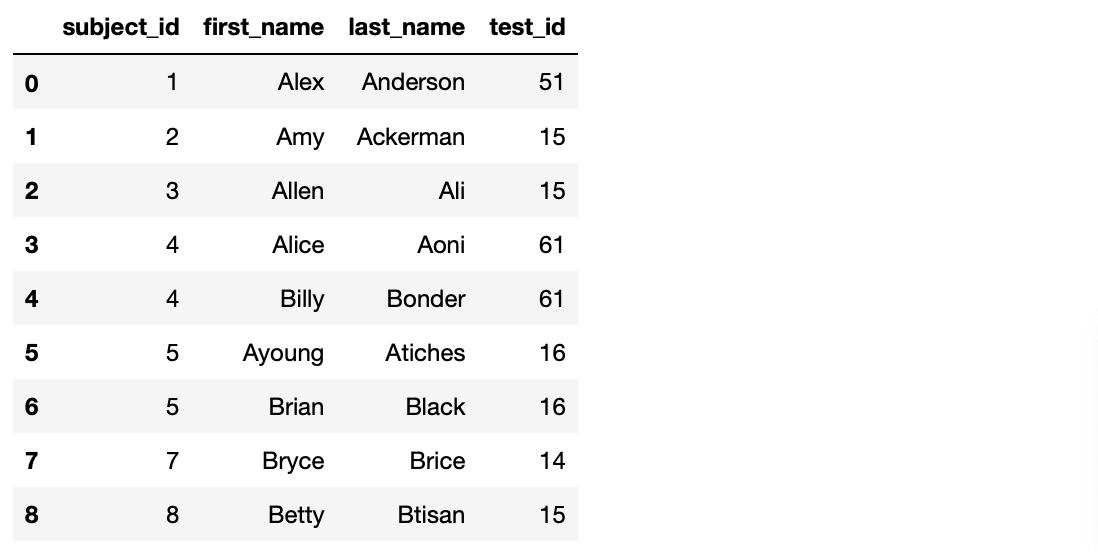
8. data1과 data2에 동일한 'subject_id'가 있는 데이터만 병합합니다.
>>> pd.merge(data1, data2, on='subject_id', how='inner') # how 인수를 통해 양쪽 데이터프레임 모두 키가 존재하는 데이터만 보여줍니다. how 인수로 명시하지 않아도 기본적으로 'inner'를 적용한 것으로 처리하기 때문에 양쪽 모두 존재하는 데이터만 보여줍니다.

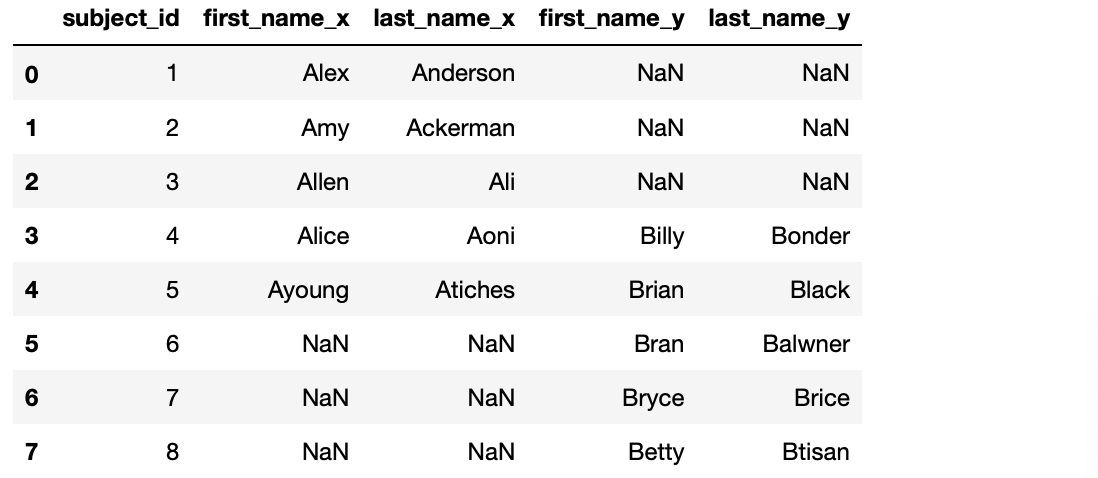
9. data1과 data2의 키 값이 한쪽에만 있더라도 모든 값들을 병합합니다.
>>> pd.merge(data1, data2, on='subject_id', how='outer') # 값이 없는 필드에는 NaN(Null 값)으로 표시합니다.
(Source : Pandas exercises 깃헙)
반응형
'파이썬으로 할 수 있는 일 > 파이썬 기초' 카테고리의 다른 글
| 시각화-visualization (Pandas 레시피) (0) | 2019.05.16 |
|---|---|
| 데이터셋 기본 통계-Stats(Pandas 레시피) (0) | 2019.05.15 |
| 커스텀 함수 적용하기-apply(Pandas 레시피) (0) | 2019.05.13 |
| 데이터셋 그룹화-GroupBy (Pandas 레시피) (0) | 2019.05.12 |
| 데이터 필터링 및 정렬(Pandas 레시피) (0) | 2019.05.11 |