ChatGPT의 가능성
ChatGPT에서 발표한 GPTs로 이제 프로그래머가 아닌 일반 사람들이 자기만의 AI를 활용할 수 있는 세상이 열리게 되었다.
상상해 보자.
친구와 대화하는 것과 마찬가지로 컴퓨터와 빠르게 소통할 수 있는 세상을!
그런 세상이 어떻게 보일까?
일상 생활 속에서 어떤 응용 프로그램을 만들어 사용할까?
이러한 인공 지능 모델의 영향은 단순한 음성 어시스턴트를 넘어서며, OpenAI의 모델 덕분에 개발자들은 이제 한때 과학 소설로만 여겨졌던 방식으로 우리의 필요를 이해하는 응용 프로그램을 만들 수 있다.
ChatGPT란?
그런데 GPT-4와 ChatGPT는 무엇일까?
먼저 이러한 인공지능 모델의 기초, 기원 및 주요 기능을 알아보도록 하자.
이러한 모델의 기본을 이해함으로써 다음 세대의 LLM 기반 응용 프로그램을 만드는 길에 한 발자국 나아갈 수 있을 것이기 때문이다.
GPT-4와 ChatGPT의 개발을 형성한 기본적인 구성 요소를 제시한다.
우리의 목표는 언어 모델과 NLP의 포괄적인 이해, 트랜스포머 아키텍처의 역할, 그리고 GPT 모델 내의 토큰화 및 예측과정을 제공하는 것이다.
LLM(대형 언어 모델)로서, GPT-4와 ChatGPT는 기계 학습(ML)과 인공 지능(AI)의 하위 분야인 자연어 처리(NLP) 분야에서 얻은 최신 유형의 모델이다.
GPT-4와 ChatGPT에 대해 알아보기 전에 NLP와 그와 관련된 분야를 살펴보는 것이 중요합니다.
AI에 대한 다양한 정의가 있지만, 대략적으로 합의되는 정의 중 하나는 AI가 일반적으로 인간 지능이 필요한 작업을 수행할 수 있는 컴퓨터 시스템의 개발이라고 말한다.
이 정의에 따라 많은 알고리즘이 AI 범주에 속한다.
예를 들어 GPS 애플리케이션에서의 교통 예측 작업이나 전략적 비디오 게임에서 사용되는 규칙 기반 시스템을 생각해보자.
이러한 예에서 기계는 외부에서 보면 이러한 작업을 수행하기 위해 지능이 필요한 것처럼 보인다.

ML은 AI의 하위 집합이다.
ML에서는 AI 시스템에서 사용되는 의사 결정 규칙을 직접 구현하지 않는다.
대신 시스템이 예제에서 스스로 학습할 수 있게 하는 알고리즘을 개발하려고 한다.
ML 연구가 시작된 1950년대 이후로 많은 ML 알고리즘이 과학 문헌에서 제안되었다다.
이 중에서도 딥러닝 알고리즘이 주목을 받았다.
딥러닝은 뇌의 구조에서 영감을 받은 알고리즘에 중점을 둔 ML의 한 분야다.
이러한 알고리즘을 인공신경망이라고 한다.
이들은 매우 큰 양의 데이터를 처리하고 이미지 및 음성 인식, 그리고 NLP와 같은 작업에서 매우 우수한 성능을 발휘할 수 있다.
GPT-4와 ChatGPT는 트랜스포머(변환자)라고 불리는 특정 유형의 딥러닝 알고리즘을 기반으로 한다.
트랜스포머(변환자)는 읽기 기계와 같이 작동한다.
문장이나 텍스트 블록의 다른 부분에 주의를 기울여 그 문맥을 이해하고 일관된 응답을 생성한다.
또한 문장 내 단어의 순서와 그 문맥을 이해할 수 있다.
이로 인해 언어 번역, 질문 응답, 텍스트 생성과 같은 작업에서 높은 효율을 발휘한다.
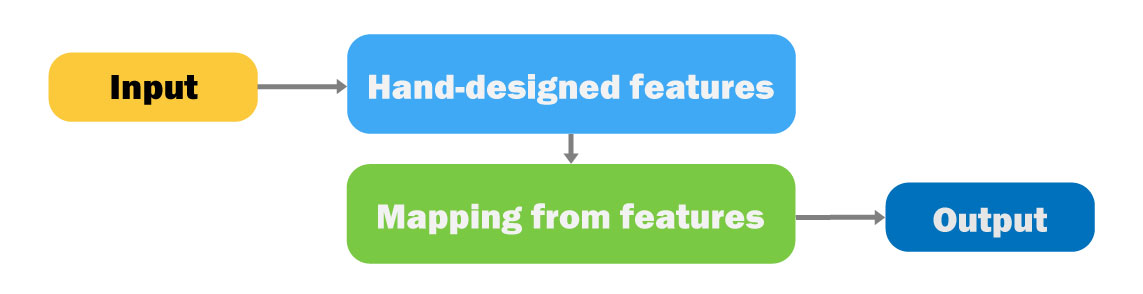
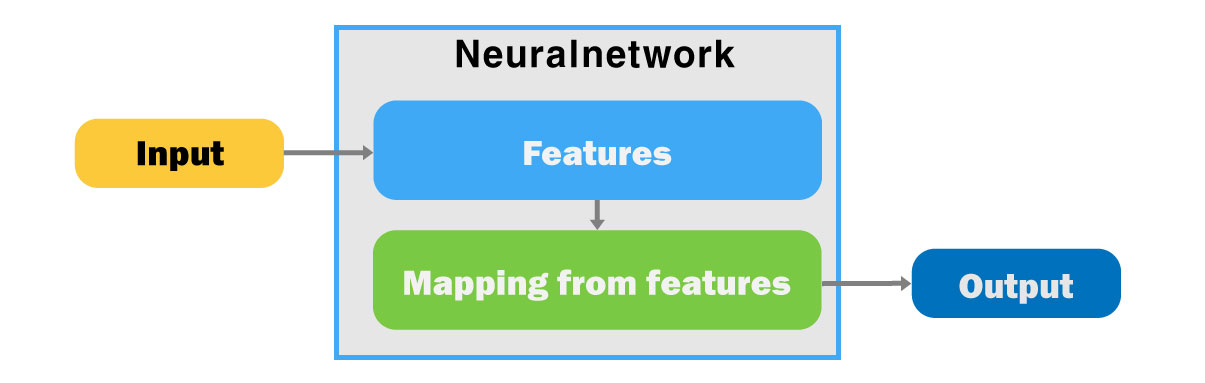
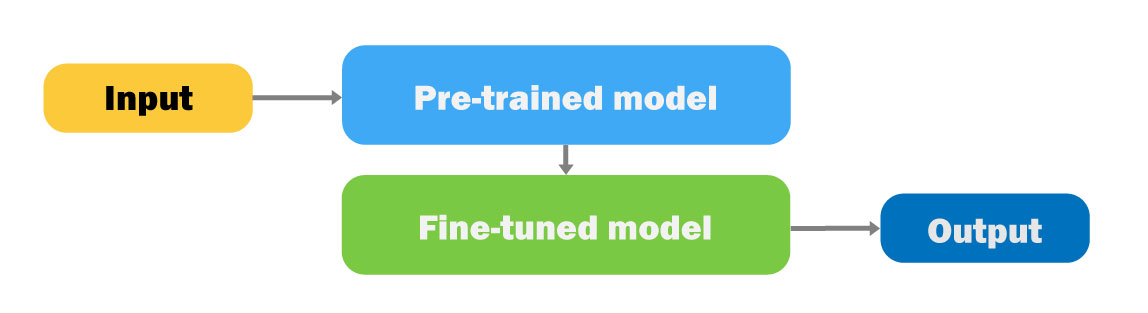
위 그림은 이러한 용어들 간의 관계를 나타나고 있다.
NLP는 컴퓨터가 자연스러운 인간 언어를 처리, 해석 및 생성할 수 있도록 하는 AI의 하위 분야다.
현대적인 NLP 솔루션은 기계 학습 알고리즘을 기반으로 한다.
NLP의 목표는 컴퓨터가 자연어 텍스트를 처리할 수 있게 하는 것이다.
이 목표는 다음과 같은 다양한 작업을 포함한다:
1. 텍스트 분류
입력 텍스트를 미리 정의된 그룹으로 분류한다.
이에는 감정 분석 및 주제 분류와 같은 작업이 포함된다.
기업은 감정 분석을 사용하여 고객이 서비스에 대한 의견을 이해할 수 있다.
이메일 필터링은 "개인", "소셜", "프로모션" 및 "스팸"과 같은 카테고리로 이메일을 분류하는 주제 분류의 예다.
2. 자동 번역
텍스트를 한 언어에서 다른 언어로 자동 번역한다.
이것은 한 프로그래밍 언어에서 다른 언어로 코드를 번역하는 작업과 같이 다양한 영역을 포함할 수 있다.
예를 들어, Python에서 C++로 코드를 번역하는 것도 포함된다.
3. 질문 응답
주어진 텍스트를 기반으로 질문에 답한다.
예를 들어, 온라인 고객 서비스 포털은 제품에 관한 FAQ를 대답하기 위해 NLP 모델을 사용할 수 있으며, 교육용 소프트웨어는 학습 주제에 관한 학생의 질문에 답변하기 위해 NLP를 사용할 수 있다.
4. 텍스트 생성
주어진 입력 텍스트(프롬프트라고도 함)를 기반으로 일관되고 관련성 있는 출력 텍스트를 생성한다.
앞서 언급한 대로 LLMs는 텍스트 생성 작업 등 다양한 작업을 해결하려는 ML 모델이다.
LLMs는 컴퓨터가 인간 언어를 처리, 해석 및 생성할 수 있게 하며, 보다 효과적인 인간-기계 커뮤니케이션을 가능하게 한다.
이를 위해 LLMs는 방대한 양의 텍스트 데이터를 분석하거나 학습하며 문장 내 단어 간의 패턴과 관계를 학습한다.
이러한 학습 프로세스를 수행하기 위해 다양한 데이터 원본을 사용할 수 있다.
이 데이터에는 Wikipedia, Reddit, 수천 권의 책의 아카이브 또는 인터넷 자체의 아카이브에서 가져온 텍스트가 포함될 수 있다.
주어진 입력 텍스트를 기반으로, 이러한 학습 프로세스를 통해 LLMs는 다음에 나올 단어에 대한 가장 가능성 있는 예측을 할 수 있으며 이를 통해 입력 텍스트에 의미 있는 응답을 생성할 수 있다.
최근 몇 달 동안 게시된 현대적인 언어 모델은 이제 텍스트 분류, 기계 번역, 질문 응답 및 기타 많은 NLP 작업과 같은 대부분의 NLP 작업을 직접 수행할 수 있는 크기와 학습된 텍스트 양이 매우 크다.
GPT-4 및 ChatGPT 모델은 텍스트 생성 작업에서 뛰어난 현대적인 LLMs이다.
파이썬으로 OpenAI API의 'Hello World' 예제 실행
OpenAI는 GPT-4와 ChatGPT를 서비스로 제공한다.
이것은 사용자가 모델의 코드에 직접 액세스하거나 자체 서버에서 모델을 실행할 수 없다는 것을 의미한다.
그러나 OpenAI는 모델의 배포 및 실행을 관리하고 사용자는 계정과 비밀 키가 있다면 이러한 모델을 호출할 수 있다.
먼저 OpenAI 웹 페이지에 로그인되어 있는지 확인하자.
API 키가 준비되었으면, OpenAI API를 사용한 첫 번째 "Hello World" 프로그램을 작성할 시간이다.
다음은 OpenAI Python 라이브러리를 사용한 첫 번째 코드 라인을 보여준다.
OpenAI가 어떻게 서비스를 제공하는지 이해하기 위해 클래식한 "Hello World" 예제를 시작하자.
먼저 pip를 사용하여 Python 라이브러리를 설치한다:
!pip install openai
다음으로 Python에서 OpenAI API에 액세스하자:
import openai
# openai ChatCompletion 엔드포인트 호출
response = openai.ChatCompletion.create(
model="gpt-3.5-turbo",
messages=[{"role": "user", "content": "Hello World!"}],
)
# 응답 추출
print(response["choices"][0]["message"]["content"])
다음과 같은 출력이 표시다:
```
안녕하세요! 오늘 어떻게 도와드릴까요?
Hello there! How may I assist you today?OpenAI Python 라이브러리를 사용하여 첫 번째 프로그램을 작성했다.
OpenAI API 키 설정
그럼 이 라이브러리를 사용하는 방법에 대해 조금 더 자세한 내용을 살펴보자.
관찰하신 대로 코드 스니펫에서 OpenAI API 키를 명시적으로 언급하지 않았다.
이것은 OpenAI 라이브러리가 자동으로 OPENAI_API_KEY라는 환경 변수를 찾도록 설계되어 있기 때문이다.
또는 다음 코드를 사용하여 API 키가 포함된 파일을 가리킬 수 있다:
# 파일에서 API 키 로드
openai.api_key_path = <경로>,또는 다음 방법을 사용하여 코드 내에서 API 키를 수동으로 설정할 수 있다:
# API 키 로드
openai.api_key = os.getenv("OPENAI_API_KEY")권장 사항은 환경 변수에 대한 널리 사용되는 규칙을 따르는 것이다.
즉, .gitignore 파일에서 소스 제어에서 제외된 .env 파일에 키를 저장하는 것이다.
그런 다음 Python에서 load_dotenv 함수를 실행하여 환경 변수를 로드하고 openai 라이브러리를 가져올 수 있다:
from dotenv import load_dotenv
load_dotenv()
import openai중요한 점은 .env 파일을 로드한 후에 openai import 선언을 가져와야 하며, 그렇지 않으면 OpenAI 설정이 올바르게 적용되지 않을 수 있다.
파이썬 코딩을 통해 프롬프트에 접근해 보면, ChatGPT와의 프롬프트를 파악하는데 도움이 될 수 있다고 본다.
하지만, 매우 빠르게 변화하고 있는 LLM모델이기 때문에, openai의 Playground에서 본인만의 AI와 만나보는 것이 더 나을 것이라 생각한다.
다음에는 Playground를 간단히 살펴보도록 할 생각이다.
https://platform.openai.com/playground
OpenAI Platform
Explore developer resources, tutorials, API docs, and dynamic examples to get the most out of OpenAI's platform.
platform.openai.com
참고문헌) Developing Apps with GPT-4 and ChatGPT
Developing Apps with Gpt-4 and Chatgpt | Caelen, Olivier - 교보문고
Developing Apps with Gpt-4 and Chatgpt |
product.kyobobook.co.kr
'파이썬으로 할 수 있는 일 > 머신러닝' 카테고리의 다른 글
| ChatGPT의 거침없는 발걸음 (0) | 2023.11.07 |
|---|---|
| 파이썬과 인공지능: 미래를 살아가는 기술 지금 당장 배우기 (0) | 2023.11.01 |
| 투자 의사결정과 AI - 바이앤홀드 전략 (0) | 2023.09.07 |
| ChatGPT에 대한 배경 및 기본 구조 이해 (0) | 2023.08.31 |
| Transformer의 기본 구조 (0) | 2022.02.10 |