1. Rule based programming

머신러닝 이전에 했던 방식으로 Input된 대상을 구별하기 위한 특징들(features)을 사람들이 직접 찾아내서, 판단할 수 있는 로직을 코딩으로 작성하여 결과(Output)을 찾아내는 방식임.
2. Hand designed feature based machine learning
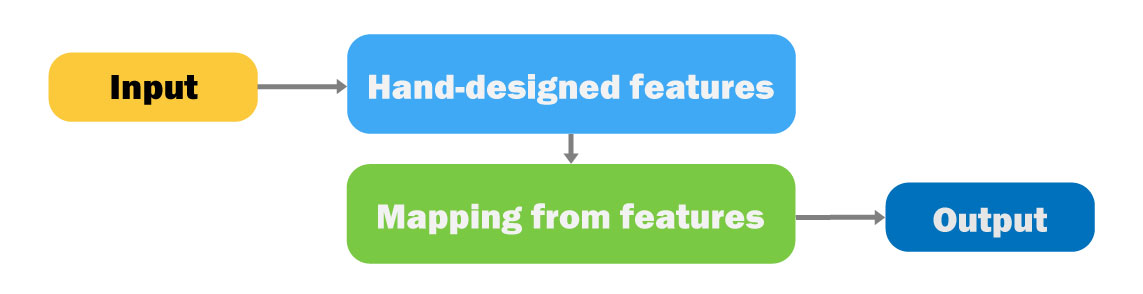
사람들이 특징들(features)을 찾아내고, 특징들에 대한 로직은 코딩 대신 머신러닝(Machine Learning)을 통해 만들어 결과(Output)을 찾아내는 방식임.
* 머신러닝(Machine Learning)에 대한 기본 이해
- 학습 단계1. 학습데이터 준비
(사람들이 직접 특징 정의하고 학습 데이터 생성을 위한 코딩 작업 수행)
1-1. 이미지 수집 → 1-2. 특징 정의 → 1-3. 학습 데이터 생성 - 학습 단계2. 모델 학습 : 최적의 연산 집합은 모든 Try 중에 Error가 제일 작은 것!
(오차를 최소화하는 연산을 찾아내는 것이 핵심으로, Try&Error 방식으로 최적의 연산 집합을 찾아냄)
2-0. 예측 및 오차 :

3. Deep Learning
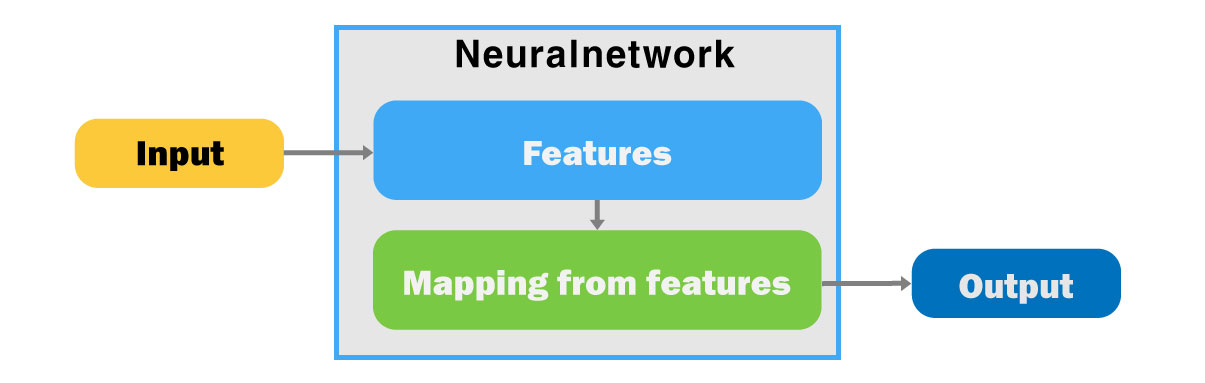
Deep&Wide Neuralnetwork : 엄청나게 많은 연산들의 집합, 자유도가 높아 연산들의 구조를 잡고 사용
구조 예) CNN, RNN, etc
※ Deep Learning(CV, NLP 차이)
- Computer Vision : 두 단계로 크게 구분
1-1 이미지 수집 → 1-2 학습 데이터 생성 - Natural Language Processing : 세 단계로 크게 구분(토큰화 과정 추가)
1-1 텍스트 수집 → 1-2 정의된 특징(토큰화, 의미분석에 용이한 토큰으로 쪼갬) → 1-3 학습 데이터 생성
4. Pre-training & Fine-tuning (GPT)
기존의 딥러닝 문제점 : 분류 대상이 (태스크가) 바뀔 때마다 다른 모델이 필요
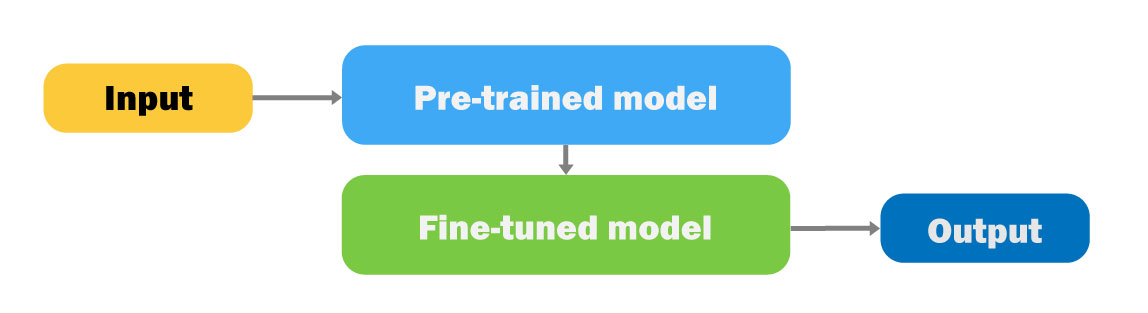
1단계 Pre-training : 모든 Image > Features > Mapping from features > 분류 결과(>1k)
2단계 Fine-tuning : 구분을 원하는 특정 이미지들을 입력
- Image input > Features(1단계에서 학습된 연산을 고정(Frozen)한 상태) > Mapping from features(테스크를 수행하기 위해 mapping쪽에 해당하는 연산들만 새로 학습) > 특정 이미지 Output
여전히 태스크마다 다른 모델이 필요하지만, 필요한 데이터 수가 적어지고 개발 속도가 올라가게 됨!
5. Big Model & zero/few shot (ChatGPT 구조)

ChatGPT를 이해하기 위해 언어 모델(Language model)에 대한 이해가 선행되어야 함.
딥러닝 초창기의 언어 처리 모델은 “RNN” 아키텍쳐로 만들어짐
- RNN(recurrent neural network), 노드 사이의 연결고리가 cycle을 이룬다고 해서 붙여진 이름으로, 자연어과 같은 sequence 형태의 데이터를 다루는데 특화되어 있음
단순한 다음 단어 맞추기가 ChatGPT롤 발전하게 된 계기?
Emergence(2017.4) :
OpenAI에서 Alec Radford가 언어 모델을 RNN으로 만들고 있었음
그런데 특정 뉴런이 감성 분석을 하고 있음을 발견함(긍정과 부정을 구분해 내는군)
언어 모델링을 하다보면 의도하지 않은 능력이 생기게 되는게 아닐까? > “Emergence”
- Alec Radford는 GPT논문의 1저자
Transformer(2017.6) :
Transformer는 RNN, CNN과 유사한 아키텍처의 일종
- “Attention”이란 항목과 항목 사이의 연관성
Transformer는 여러모로 성능이 좋았음. 계산 효율이 기존의 RNN 등에 비해 대단히 높았던게 이점, 게다가 결과의 품질도 더 좋음 > 이후 비전, 추천, 바이오 등 다른 모든 분야에서 쓰는 기술이 됨.
Alec Radford도 자연스럽게 Transformer를 가지고 실험하기 시작함.
GPT(2018.6) :
Alec Radford와 동료인 Ilya Sutskever 등이 RNN에서 Transformer로 넘어가며 출판
“Generative pretraining(GP)”을 하는 Transformer(T)
Pretraining-finetuning 패러다임의 대표적인 논문 – 큰 스케일에서 언어 모델링을 통해 사전학습 모델을 만들고, 이 모델을 파인튜닝하면 다양한 NLP 태스크에서 좋은 성능을 보임.
GPT-2(2019.2) :
Ilya Sutskever가 오랫동안 주장했던 믿음은 “데이터를 많이 부어 넣고 모델 크기를 키우면 신기한 일들이 일어난다”였음
Transformer 전까지는 큰 모델의 학습을 어떻게 할 것인가가 문제였는데, Transformer가 계산 효율이 높아 스케일링에 유리
모델을 키우고(117M > 1.5B)데이터를 왕창 부음(4GB > 40GB) -> GPT-2의 탄생
생성에 너무 뛰어나서 해당 모델이 가짜 정보를 다량 생성할 위험성이 크다고 판단, OpenAI는 GPT-2를 공개하지 않는다고 함
언어 생성을 아주 잘하게 될 뿐더러 emergence!가 또 보임
GPT2는 방대한 데이터를 기반으로 세상에 대해 많이 배운 모델
- emergence!:Zero-shot learning : 예시를 전혀 보지 않고, 모델 업데이트 없이 새로운 태스크를 수행
“Unsupervised multitask learners, 하나를 가르쳤는데 열을 아네”
독해, 번역, 요약 Q&A 등에 대해 zero-shot 능력이 꽤 있음!
Zero-shot인데도 특정 태스크는 기존의 SOTA 모델들을 짓눌러버림 - SOTA란 state-of-the-art, 즉 현존하는 제일 좋은 모델
GPT-3(2020.6) :
여기서 한 번 더 크기를 키운 것이 GPT-3(모델 1.5B > 175B, 데이터 40GB > 600GB+)
많은 데이터로 pretraining해서 더욱 놀라운 생성 능력을 갖추게 됨
역시 여러 측면으로 “emergence”를 확인:
지식을 포함?(world knowledge), 학습 없이 태스크를 배우는 능력?(few-shot learners)
- “Emergence”: In-context learning, Few-shot도 모델 파인튜닝 없이 되네? : 프롬프트에 예시 몇 개(“few-shot”)를 넣어주면 모델 업데이트 없이 새로운 태스크를 수행
GPT-4 출현 :
CLIP(2021.1) : “zero-shot” 이미지 분류
DALL-E(2021.1): 주어진 텍스트로부터 이미지 생성
Codex(2021.8) : 코드 생성을 위한 모델
InstructGPT(2022.1) : 명령에 대한 파인튜닝과 강화학습 > 이미 지식은 다 있다, 어떻게 뽑아낼 것인가

※ 위 정보는 fastcampus.co.kr의 업스테이지 '모두를 위한 ChatGPT UP!'의 강의 내용에서 요약 정리한 것입니다. 구체적인 내용을 배우시려면 업스테이지 강의를 들으시면 많은 도움이 되실 겁니다!
'파이썬으로 할 수 있는 일 > AI&머신러닝' 카테고리의 다른 글
| 파이썬과 인공지능: 미래를 살아가는 기술 지금 당장 배우기 (0) | 2023.11.01 |
|---|---|
| 투자 의사결정과 AI - 바이앤홀드 전략 (0) | 2023.09.07 |
| Transformer의 기본 구조 (0) | 2022.02.10 |
| 머신러닝 용어들(NLP, CV) (0) | 2021.07.19 |
| 데이터 정제(Data Cleaning)와 정규화(Normalizing) : 사이킷런(Scikit-learn) 기초 (0) | 2019.05.27 |



