컴퓨터 비전이나 텍스트 분석은 성능 좋은 오픈 API나 노하우가 축적되고 공유되어 빠르게 발전하고 있다. 하지만 투자 업계에서는 금융 데이터를 손쉽게 처리해주는 판다스 같은 라이브러리가 있어도, 성능 좋은 알고리즘이나 방법론이 공유되는 경우가 거의 없다.
세계 경제가 긴밀하게 연동하고 경제 주체들의 투자 패턴이 다양해짐에 따라 고려해야 할 변수가 기하급수적으로 증가한 반면 시계열 데이터를 기본으로 한 투자 데이터는 그 양이 한정적이다. 애널리스트 분석에 자주 사용되는 OECD 경기선행지수, 국가별 GDP, 금리 자료 등은 업데이트 주기가 길다. 이러한 데이터의 한계로 인해 좋은 모델을 만들기가 어렵다고 한다.
금융은 자본주의 사회에서 우리의 삶에 깊숙이 침투하여 개인의 일상생활과 밀접한 관계를 맺고 있고 우리가 살아가며 생산하는 수많은 데이터를 통해 연결되어 있다. 많은 의사결정 프로세스가 데이터 기반으로 전환하는 시대에 투자라고 예외일 수 없다. 나날이 복잡다단해지는 투자 환경에서 사람의 '감'에 기반한 투자 의사결정은 점점 힘을 잃어갈 것이다.
투자 영역에서 활용하는 데이터('실전 금융 머신러닝 완벽분석'의 저자인 마르코스 로페즈가 분류)
| 재무제표 데이터 | 마켓 데이터 | 분석 데이터 | 대체 데이터 |
| 자산 | 가격/변동성 | 애널리스트 추천 | 위성/CCTV 이미지 |
| 부채 | 거래량 | 신용 등급 | 구글 검색어 |
| 판매량 | 배당 | 이익 예측 | 트윗/SNS |
| 비용/이익 | 이자율 | 감성 분석 | 메타데이터 |
| 거시 변수 | 상장/폐지 | ... | ... |
파이썬으로 만드는 투자전략과 주요 지표
1. 바이앤홀드(Buy & Hold) 전략
바이앤홀드는 주식을 매수한 후 장기 보유하는 투자 전략이다. 즉 매수하려는 종목이 충분히 저가라고 판단될 때 주기적으로 매수한 후 장기간 보유하는 식으로 투자하는 방법이다.
주가는 예측이 불가하지만 경제가 성장함에 따라 장기적으로 우상향한다는 투자 철학의 관점에서 보면 합리적인 투자 방법이다.
주피터 노트북(Jupyter notebook) 환경에서 실행한다고 가정하고, 관련 라이브러리를 다음과 같이 설치해야 한다.
!pip install matplotlib
!pip install pandas
!pip install -U finance-datareader # 국내 금융데이터를 포함 pandas-datareader를 대체준비가 되면, 관련 라이브러리를 불러온다
import pandas as pd
import numpy as np
import FinanceDataReader as fdr본격적으로 바이앤홀드 전략을 구현해 보자. FinanceDataReader 라이브러리에서 직접 테슬라(TSLA) 데이터를 추출하여, 판다스의 head()함수를 사용해 데이터를 살펴본다.
df = fdr.DataReader('TSLA', '2013-01-01', '2023-08-31')
df.head()
데이터는 'Date'가 인덱스로 설정되고, 시작가(Open), 고가(High), 저가(Low), 종가(Close), 수정 종가(Adj Close), 거래량(Volume)으로 구성된다.
결측치(데이터에 값이 없는 것, NA)가 있는 지 살펴본다.
df.isin([np.nan, np.inf, -np.inf]).sum()
결측치가 없는 것을 확인했으니, 바이앤홀드 전략을 수정 종가(Adj Close)를 이용해 테스트한다.
보통 전략을 테스트할 때는 종가를 기준으로 처리한다.
수정 종가를 슬라이스해 별도의 데이터셋을 만든다.
price_df = df.loc[:,['Adj Close']].copy()
price_df.plot(figsize=(16,9))
수정 종가(Adj Close)로 DataFrame을 만들고 종가(Close) 모양이 어떻게 생겼는지 그래프를 통해 살펴본다.
전체 기간을 보면 주가가 많이 상승했다. 하지만 짧은 시점을 확인해 보면 다를 수 있다.
테슬라는 최근 2022~2023년에 주가 변동성이 매우 큰 것을 알 수 있다.
from_date = '2022-01-01'
to_date = '2023-08-31'
price_df.loc[from_date:to_date].plot(figsize=(16,9))
2022년 400달러에 달하던 주가가 108달러까지 떨어지는 등 최고점 투자 대비 70% 가량까지 하락했다.
이렇게 최고점 대비 현재까지 하락한 비율 중 최대 하락률을 최대 낙폭(maximum draw down, MDD)이라고 한다.
그 다음으로 일별 수익률을 계산해 보자.
price_df['daily_rtn'] = price_df['Adj Close'].pct_change()
price_df.head(10)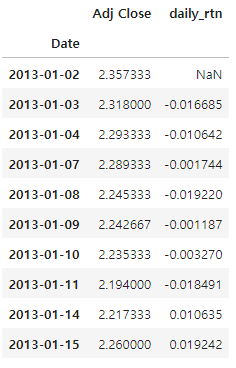
바이앤홀드 전략에서 일별 수익률을 계산하는 이유는 매수한 시점부터 매도한 시점까지 보유하게 되는데 일별 수익률을 누적으로 곱하면 최종적으로 매수한 시점 대비 매도한 시점의 종가 수익률로 계산되기 때문이다.
다음에는 바이앤홀드 전략의 누적 곱을 계산해 보자. 판다스 cumprod() 함수를 사용하면 쉽게 계산된다.
price_df['st_rtn'] = (1+price_df['daily_trn']).cumprod()
price_head(10)
price_df['st_rtn'].plot(figsize=(16,9))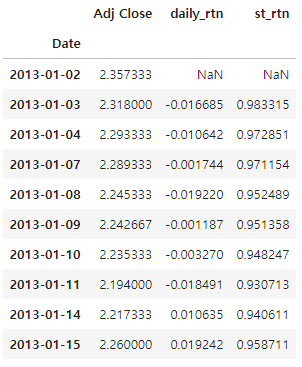

이번에는 매수 시점을 정해서 수익률을 계산해 본다.
base_date= '2020-01-02'
tmp_df = price_df.loc[base_date:,['st_rtn']] / price_df.loc[base_date,['st_rtn']]
last_date = tmp_df.index[-1]
print('누적 수익 : ',tmp_df.loc[last_date,'st_rtn'])
tmp_df.plot(figsize=(16,9))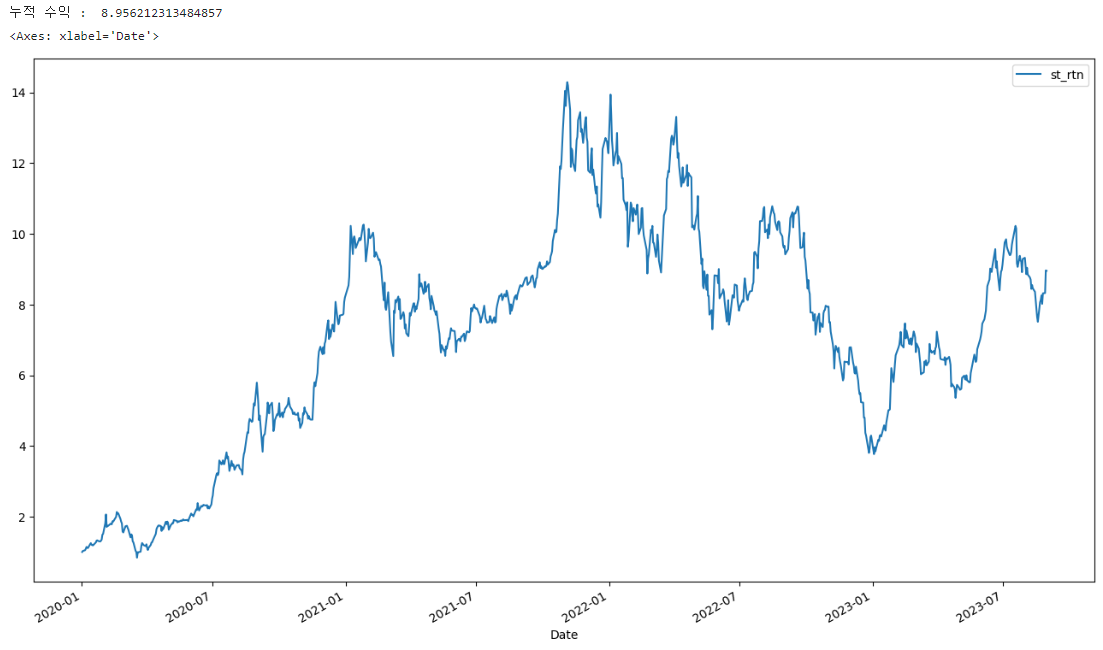
base_date변수를 선언해 새로운 기준 일자를 정한다. 특정 일자를 기준으로 수익률을 계산하고 누적 수익을 보니 8.95까지 상승했다. 2020년 1월 2일에 처음 테슬라 주식을 매수했다면 8.95배의 수익률을 얻을 수 있었다는 뜻이다.
사실 지금 보여준 바이앤홀드 전략에는 복잡한 코딩은 없었다. 단지 주어진 기간의 수익률만 확인했을 뿐이다.
여기에 신호(매수/매도 신호)를 추가한다면 다양한 전략으로 응용할 수 있다.
- 연평균 복리 수익률(CAGR)
수익률 성과를 분석할 때 산술평균 수익률보다 기하평균 수익률을 더 선호한다. 기하평균 수익률이 복리 성질과 주가 변동이 심한 때에 따라 변동성을 표현해 주기 때문이다.
이 CAGR 수식을 파이썬 코드로 구현하면 다음과 같다.
CAGR = price_df.loc['2023-08-30', 'st_rtn'] ** (252./len(price_df.index)) -1우리가 가진 데이터셋의 마지막 날짜가 2023년 8월 30일이다. 해당일자의 최종 누적 수익률의 누적 연도 제곱근을 구하는 것이다. 또한 우리는 일(Daily) 데이터를 사용했으므로 전체년도를 구하기 위해 전체 데이터 기간을 252(금융공학에서 1년은 252 영업일로 계산)로 나눈 역수를 제곱(a**b) 연산한다. 그리고 -1을 하면 수익률이 나온다.
- 최대 낙폭(MDD)
최대 낙폭은 최대 낙폭 지수로, 투자 기간에 고점부터 저점까지 떨어진 낙폭 중 최댓값을 의미한다. 이는 투자자가 겪을 수 있는 최대 고통을 측정하는 지표로 사용되며, 낮을수록 좋다.
이 MDD 수식을 파이썬 코드로 구현하면 다음과 같다.
historical_max = price_df['Adj Close'].cummax()
daily_drawdown = price_df['Adj Close'] / historical_max - 1.0
historical_dd = daily_drawdown.cummin()
historical_dd.plot()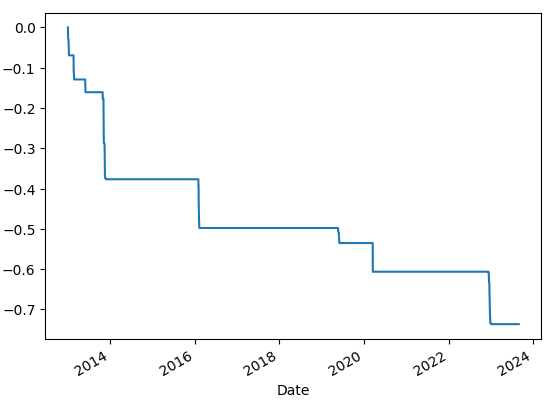
수정 종가에 cummax() 함수 값을 저장한다. cummax()는 누적 최댓값을 반환한다. 전체 최댓값이 아닌 행row별 차례로 진행함녀서 누적 값을 갱신한다. 현재 수정 종가에서 누적 최댓값 대비 낙폭률을 계산하고 cummin() 함수를 사용해 최대 하락률을 계산한다. 출력 그래프를 보면 최대 하락률의 추세를 확인할 수 있다.
- 변동성(Vol)
주가 변화 수익률 관점의 변동성을 알아보자. 변동성은 금융 자산의 방향성에 대한 불확실성과 가격 등락에 대한 위험 예상 지표로 해석하며, 수익률의 표준 편차를 변동성으로 계산한다.
만약 영업일 기준이 1년에 252일이고 일별 수익률의 표준 편차가 0.01이라면, 연율화된 변동성은 다음 수식과 같이 계산된다.
변동선 수익을 파이썬 코드로 구현하면 다음과 같다.
VOL = np.std(price_df['daily_rtn']) * np.sqrt(252.)변동성은 수익률의 표준편차로 계산한다. 이는 일Daily 단위 변동성을 의미하는데, 루이 바슐리에의 '투기이론'에서 주가의 변동폭은 시간의 제곱근에 비례한다는 연구 결과에 따라 일 단위 변동성을 연율화할 때 252의 제곱근을 곱한다.
- 샤프 지수
샤프 지수는 위험 대비 수익성 지표라고 볼 수 있다.
샤프 지수를 파이썬 코드로 구현하면 다음과 같다.
Sharpe = np.mean(price_df['daily_rtn']) / np.std(price_df['daily_rtn']) * np.sqrt(252.)사후적 샤프 비율을 사용했다. 실현 수익률의 산술평균/실현 수익률의 변동성으로 계산하므로 넘파이의 평균을 구하는 함수와 연율화 변동성을 활용해 위험 대비 수익성 지표를 계산한다.
- 성과 분석 결과
최종 성과를 분석해 보자.
CAGR = price_df.loc['2023-08-30', 'st_rtn'] ** (252./len(price_df.index)) -1
Sharpe = np.mean(price_df['daily_rtn']) / np.std(price_df['daily_rtn']) * np.sqrt(252.)
VOL = np.std(price_df['daily_rtn']) * np.sqrt(252.)
MDD = historical_dd.min()
print('CAGR : ',round(CAGR*100,2), '%')
print('Sharpe : ',round(Sharpe,2))
print('VOL : ',round(VOL*100,2), '%')
print('MDD : ',round(-1*MDD*100,2), '%')CAGR : 55.34%
Sharpe : 1.06
VOL : 57.18%
MDD : 73.63%
테슬라는 2013년부터 현재(2023년 8월 30일 기준)까지 연평균 복리 수익률 CAGR로 55% 성장했다. 샤프 지수 Sharpe는 1 이상만 되어도 좋다고 판단한다.
다음으로 변동성 VOL을 보면 57%인 것을 확인할 수 있는데, 이는 주가 수익률이 꽤 많이 출렁인 것을 의미한다. 장기간의 시점에서 주가를 바라볼 때는 안정적으로 우상향했다고 생각할 수 있지만, 하루하루 주가 흐름은 그닥 안정적이지 않았다는 뜻이다.
마지막으로 최대 낙폭 MDD는 73%가 하락한 경우가 있음을 알 수 있다. 최고점에서 주식을 구입한 경우에는 견디가 어려운 낙폭임을 인지할 필요가 있다.
기업 성장성이 확실하다고 판단한 주식은 싸다고 생각되는 시장이 어려운 시기에 사서 장기적으로 보유하다가 고점이라고 생각되는 시점인 대중이 열광하는 시점에 처분한다는 자세를 잊지 말아야겠다.
'파이썬으로 할 수 있는 일 > AI&머신러닝' 카테고리의 다른 글
| ChatGPT의 거침없는 발걸음 (0) | 2023.11.07 |
|---|---|
| 파이썬과 인공지능: 미래를 살아가는 기술 지금 당장 배우기 (0) | 2023.11.01 |
| ChatGPT에 대한 배경 및 기본 구조 이해 (0) | 2023.08.31 |
| Transformer의 기본 구조 (0) | 2022.02.10 |
| 머신러닝 용어들(NLP, CV) (0) | 2021.07.19 |



