이번에는 pandas에서 데이터를 삭제하는 방법에 대해 알아보고자 합니다.
1. pandas, numpy 라이브러리를 불러들입니다.
>>> import pandas as pd
>>> numpy as np
2. 다음 주소에서 데이터셋을 읽어들입니다.
>>> url = 'https://archive.ics.uci.edu/ml/machine-learning-databases/wine/wine.data'
3. 읽어들인 데이터셋을 wine 변수에 저장합니다.
>>> wine = pd.read_csv(url)
>>> wine.head()

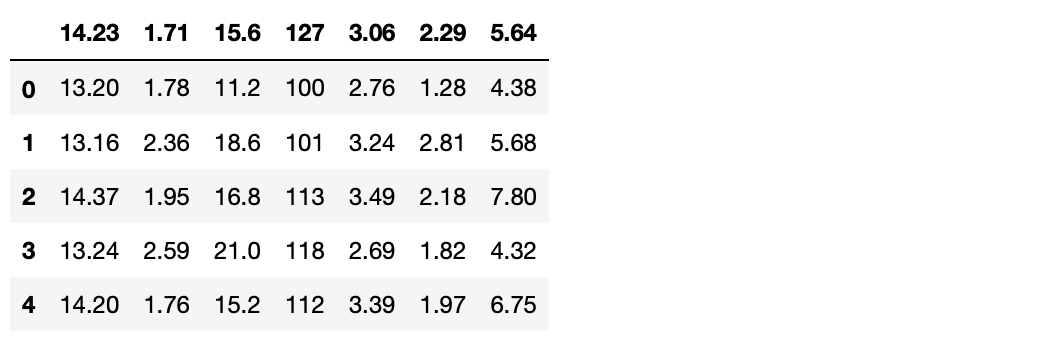
4. 컬럼들 중에서 첫번째, 네번째, 일곱번째, 아홉번째, 열두번째, 열세번째, 열네번째 컬럼을 삭제합니다.
>>> wine = wine.drop(wine.columns[[0, 3, 6, 8, 11, 12, 13]], axis=1) # drop 메서드를 사용해서, 컬럼을 삭제합니다. axis=1 인수로 열을 삭제한다는 것을 명시합니다.
>>> wine.head()
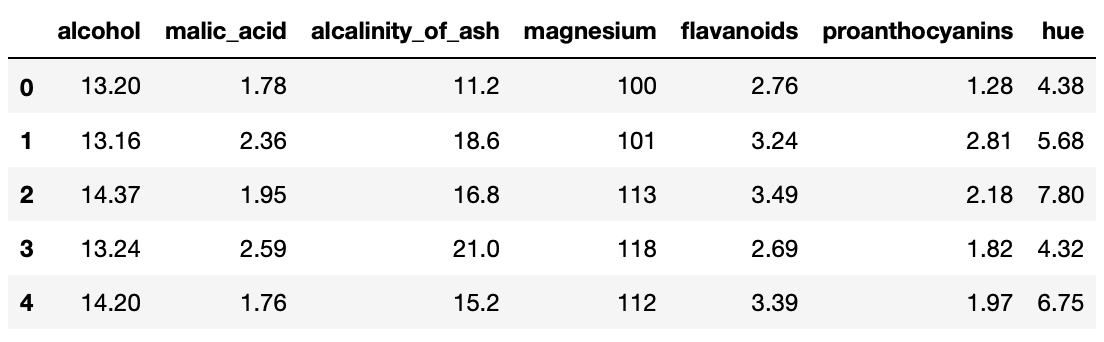
5. 아래와 같이 열을 지정합니다.
1) alcohol 2) malic_acid 3) alcalinity_of_ash 4) magnesium 5) flavanoids 6) proanthocyanins 7) hue
>>> wine.columns = ['alcohol', 'malic_acid', 'alcalinity_of_ash', 'magnesium', 'flavanoids', 'proanthocyanins', 'hue']
>>> wine.head()
6. alcohol 컬럼 첫 3행의 값을 NaN으로 설정합니다.
>>> wine.iloc[0:3, 0] = np.nan # iloc 메서드로 첫번째 열(0)부터 세번째 열(2)에, 첫번째 컬럼(0)에 적용합니다. 0부터 시작입니다.
>>> wine.head()

7. magnesium 컬럼의 3, 4행 값을 NaN으로 설정합니다.
>>> wine.iloc[2:4, 3] = np.nan # iloc 메서드로 세번째 열(2)부터 네번째 열(3)에, 세번째 컬럼(3)에 적용합니다. 0부터 시작입니다.
>>> wine.head()

8. alcohol 컬럼의 NaN 값을 10으로 채우고, magnesium 컬럼의 NaN은 100으로 채웁니다.
>>> wine.alcohol.fillna(10, inplace = True) # fillna 메서드로 NaN 값을 10으로 바꿉니다. inplace=True로 다른 객체를 만드는 게 아니라 기존 객체를 바꿉니다.
>>> wine.magnesium.fillna(100, inplace = True)
>>> wine.head()
9. 결측 값의 숫자를 합산합니다.
>>> wine.isnull().sum() # 결측 값을 가진 데이터가 없습니다.

10. 10까지의 범위에서 랜덤으로 숫자 배열을 생성합니다.
>>> random = np.random.randint(10, size = 10)
>>> random

11. 생성한 난수를 인덱스로 사용하고 각 셀에 NaN 값을 할당합니다.
>>> wine.alcohol[random] = np.nan
>>> wine.head(10)

12. 얼마나 많은 결측 값이 있는지 확인합니다.
>>> wine.isnull().sum()

13. 결측 값을 가진 행들을 삭제합니다.
>>> wine = wine.dropna(axis=0, how = 'any') # dropna 메서드로 결측값을 찾습니다. axis=0으로 행을 선택하고, how='any'로 하나라도 결측값이 있는 경우를 포함합니다.
>>> wine.head()

14. 인덱스를 재설정합니다.
>>> wine = wine.reset_index(drop = True)
>>> wine.head()
(Source : Pandas exercises 깃헙)
'파이썬으로 할 수 있는 일 > 파이썬 기초' 카테고리의 다른 글
| jupyter notebook 원격 접속 설정 (1) | 2022.03.08 |
|---|---|
| git과 github 기본 명령어 정리 (0) | 2020.01.05 |
| 시계열 처리- Time series (Pandas 레시피) (0) | 2019.05.17 |
| 시각화-visualization (Pandas 레시피) (0) | 2019.05.16 |
| 데이터셋 기본 통계-Stats(Pandas 레시피) (0) | 2019.05.15 |