최근 AI비서, ARS 등 언어 처리에 대한 분야에서 많이 사용되는 딥러닝 아키텍처인 Transformer에 대해 공부중이다.
공부한 내용을 정리하면 좀 더 기억이 잘 되기에 기록을 남겨본다.
RNN과 LSTM 네트워크는 다음 단어 예측, 기계 번역, 텍스트 생성 등의 태스크에서 사용되어 왔었다.
하지만 트랜스포머가 발표된 후에는 트랜스포머에게 자리를 내주었다고 할 수 있다.
트랜스포머가 출연하면서 자연어 처리 분야가 획기적으로 발전하고, 이를 기반으로 한 BERT, GPT-3, T5 등과 같은 아키텍처가 나오게 되었다.
트랜스포머는 RNN에서 사용한 순환 방식을 사용하지 않는다.
대신 셀프 어텐션(self-attention)이라는 특수한 형태의 어텐션을 사용한다.
트랜스포머는 인코더-디코더로 구성된 모델이다.
인코더에 원문을 입력하면 인코더는 원문의 표현 방법을 학습시키고 그 결과를 디코더로 보낸다.
디코더는 인코더에서 학습한 표현 결과를 가지고 사용자가 원하는 문장을 생성한다.
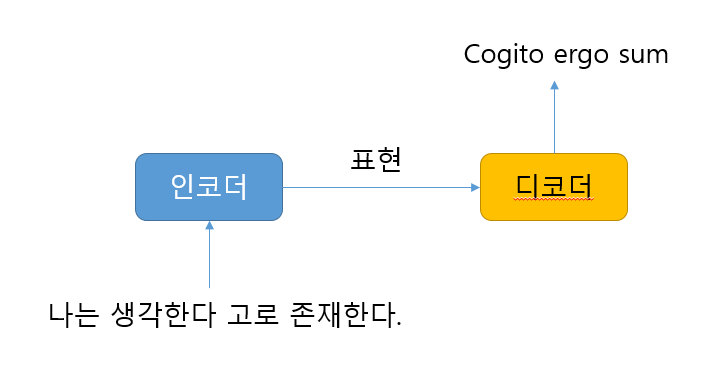
인코더와 디코더의 구체적인 이해는 다음에 하기로 한다.
대신 Transformer를 기반으로 한 BERT의 특징에 대해 정리해 본다.
BERT(Bidirectional Encoder Representation from Transformer)는 구글에서 2018년 발표한 최신 임베딩 모델이다. 대량의 영어 데이터로 학습된 사전학습 언어 모델로 질문에 대한 대답, 텍스트 생성, 문장 분류 등과 같은 태스크에사 가장 좋은 성능을 도출해 자연어 처리 분야에 크게 기여해 왔다.
BERT의 특징
- Masked Language Model(MLM) : 어떤 문장의 특정 부분을 Masking처리하여 모델이 Masking 처리된 부분을 예측하도록 학습시키는 방식
- Next Sentence Prediction(NSP) : 두 문장이 이어지는 문장인지 아닌지 맞히도록 학습
- 자기지도 학습 : 학습 Label을 사람이 직접 만들지 않고 스스로 만든 데이터를 학습함으로써 언어의 기본 소양을 쌓음. 이처럼 스스로 정답이 있는 학습 데이터를 만들어 학습하는 방식을 자기지도학습(Self-supervised Learning)이라고 하고 이러한 방식으로 만들어진 언어 모델을 사전학습 모델(Pre-trained Language Model)이라고 한다.
- 전이학습(Transfer Learning) : 사전학습 모델을 기반으로 특정 태스크를 위해 한번 더 학습하는 방식을 전이학습이라고 하고, 이 학습 단계를 파인튜닝(Fine tuning)단계라고 한다. 파인튜닝이란 사전학습 모델을 기반으로 특정 태스크를 위해 딥러닝 모델을 미세하게 조정하는 학습 과정을 말한다.
태스크 활용 사례 : 사전학습 모델은 모델 자체로 특정 기능을 수행할 수 없다. 하지만 파인 튜닝을 통해 여러 다양한 태스크에 활용이 가능하다.
* RNN(Recurrent Neural Networks) 순환신경망 : 긴 문장의 의미를 파악하고 해당 문장이 의미하는 것이 무엇인지 예측하기 위한 방법으로 쉽게 말해 '여러개의 단어를 입력받게 되었을 때 앞에 입력받은 단어(토큰)을 잠시 기억하고 있다가 이 단어가 얼마나 중요하지 분석해 가중치를 담아 다음 단계로 넘기는 구조로 되어 있다.
* LSTM(Long Short Term Memory) 장단기 메모리 : RNN 기법의 하나로 기존 RNN의 문제인 기울기 소멸 문제(vanishing gradient problem)를 방지하기 위해 개발되었다.
'파이썬으로 할 수 있는 일 > 머신러닝' 카테고리의 다른 글
| 투자 의사결정과 AI - 바이앤홀드 전략 (0) | 2023.09.07 |
|---|---|
| ChatGPT에 대한 배경 및 기본 구조 이해 (0) | 2023.08.31 |
| 머신러닝 용어들(NLP, CV) (0) | 2021.07.19 |
| 데이터 정제(Data Cleaning)와 정규화(Normalizing) : 사이킷런(Scikit-learn) 기초 (0) | 2019.05.27 |
| 선형 회귀분석(Linear Regression) : 사이킷런(Scikit-learn) 기초 (0) | 2019.05.23 |

