반응형
1. pandas 라이브러리를 읽어들입니다.
>>> import pandas as pd
2. 아래 url 주소에서 데이터셋을 읽어들입니다.
>>> url = 'https://raw.githubusercontent.com/justmarkham/DAT8/master/data/chipotle.tsv'
>>> chipo = pd.read_csv(url, sep='\t') # 탭 구분자로 되어 있는 데이터셋을 읽어들임
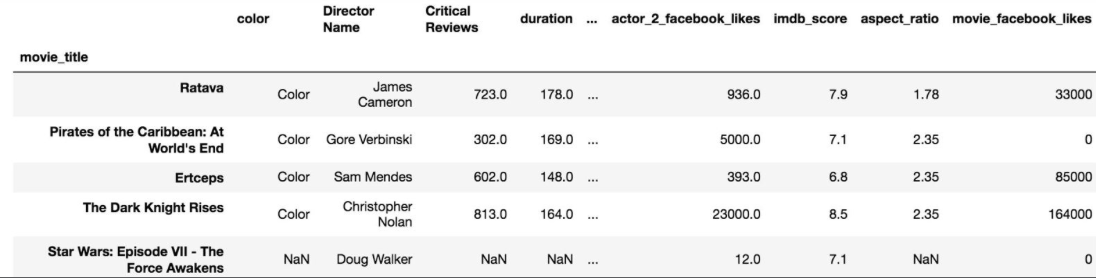
>>> chipo.head() # chipo의 데이터 구조 파악을 위해 상위 5개 데이터셋을 조회

>>> chipo.dtypes # item_price 컬럼의 타입이 object인 것을 확인함(가격 계산을 위해 float으로 바꿀 것임)

>>> prices = [float(value[1 : -1]) for value in chipo.item_price] # item_price컬럼 값을 for 반복문으로 읽고 맨 앞의 $를 제외한 후 float으로 변경하여 prices 변수에 저장함
>>> chipo.item_price = prices # float 타입의 가격을 데이터셋의 item_price에 재할달함
>>> chipo_filtered = chipo.drop_duplicates(['item_name', 'quantity']) # 아이템 이름과 수량이 중복되는 열들을 제외한 후 chipo_filtered 변수에 저장
>>> chipo_one_prod = chipo_filtered[chipo_filtered.quantity == 1] # 수량이 1인 제품들만 선택하여 chip_one_prod 변수에 저장
>>> chipo_one_prod[chipo_one_prod['item_price']>10.item_name.nunique() # 가격이 10보다 큰 아이템 이름들의 숫자를 알려줌(12개), item_name.unique()로 조회하면, 아래와 같이 배열로 보여줌

3. 각 아이템별 가격은 얼마인가?
>>> chipo[(chipo['item_name'] == 'Chicken Bowl') & (chipo['quantity'] == 1 # 아이템 중 'Chicken Bowl'을 선택하고 수량은 한 개인 경우라는 조건을 걸어 chipo 데이터셋에서 조회

4. 아이템 이름으로 정렬하기
>>> chipo.item_name.sort_values() # 또는
>>> chipo.sort_values(by = 'item_name') # 아이템 이름으로 chipo 데이터셋을 정렬

5. 주문한 아이템 중 아이템 가격이 가장 비싼 아이템의 수량은 얼마인가?
>>> chipo.sort_values(by = 'item_price', ascending = False).head(1) # 내림차순으로 아이템 가격을 정렬하기 위해 ascending = Fasle로 설정한 후, head(1)로 가장 상위의 열을 가져옴

6. 주문한 채소 샐러드 접시는 몇 번이나 주문했는가?
>>> chipo_salad = chipo[chipo.item_name == 'Veggie Salad Bowl'] # chipo 데이터셋의 아이템 이름이 'Veggie Salad Bowl'인 데이터셋만 chipo_salad 변수에 저장함
>>> len(chipo_salad) # 18개가 결과로 나타남
7. 얼마나 많은 사람이 하나 이상의 캔 소다를 주문했는가?
>>> chipo_drink_steak_bowl = chipo[(chipo.item_name == 'Canned Soda') & (chipo.quantity > 1)] # 아이템 이름이 'Canned Soda'와 수량이 1개보다 큰 데이터셋을 chipo_drink_steak_bowl 변수에 저장함
>>> len(chipo_drink_steak_bowl) # 20개가 결과로 나타남
(Source : Pandas_exercises 깃헙)
반응형
'파이썬으로 할 수 있는 일 > 파이썬 기초' 카테고리의 다른 글
| 커스텀 함수 적용하기-apply(Pandas 레시피) (0) | 2019.05.13 |
|---|---|
| 데이터셋 그룹화-GroupBy (Pandas 레시피) (0) | 2019.05.12 |
| index 및 columns 이름 재설정(Pandas 레시피) (0) | 2019.05.10 |
| 파이썬으로 데이터 분석에 도전해 보자 (0) | 2019.01.31 |
| Pandas의 index에 대해 (0) | 2018.11.30 |