듀얼 모멘텀은 투자 자산 가운데 상대적으로 상승 추세가 강한 종목에 투자하는 상대 모멘텀 전략과 과거 시점 대비 현재 시점의 절대적 상승세를 평가한 절대 모멘텀 전략을 결합해 위험을 관리하는 투자 전략이다.
- 모멘텀(momentum)은 물질의 운동량이나 가속도를 의미하는 물리학 용어로, 투자 분야에서는 주가가 한 방향성을 유지하려는 힘을 의미한다.
듀얼 모멘텀 전략은 국내에서도 많은 미디어에 소개되며 대중에게 익숙한 퀀트 투자 전략이기도 하다.
듀얼 모멘텀 전략을 구현하기 위해서는 먼저 절대 모멘텀과 상대 모멘텀을 이해하고 구현할 수 있어야 한다.
최근 N개월간 수익률이 양수이면 매수하고 음수이면 공매도하는 전략을 절대 모멘텀 전략이라고 한다.
반면에 상대 모멘텀 전략은 투자 종목군이 10개 종목이라 할 때 10개 종목의 최근 N개월 모멘텀을 계산해 상대적으로 모멘텀이 높은 종목을 매수하고 상대적으로 낮은 종목은 공매도하는 전략이다.
이번에는 절대 모멘텀 전략을 실행해 보도록 한다.
절대 모멘텀 전략
먼저 필요한 라이브러리들을 가져오고, 분석할 데이터셋을 읽어온다.
import pandas as pd
import numpy as np
import FinanceDataReader as fdr
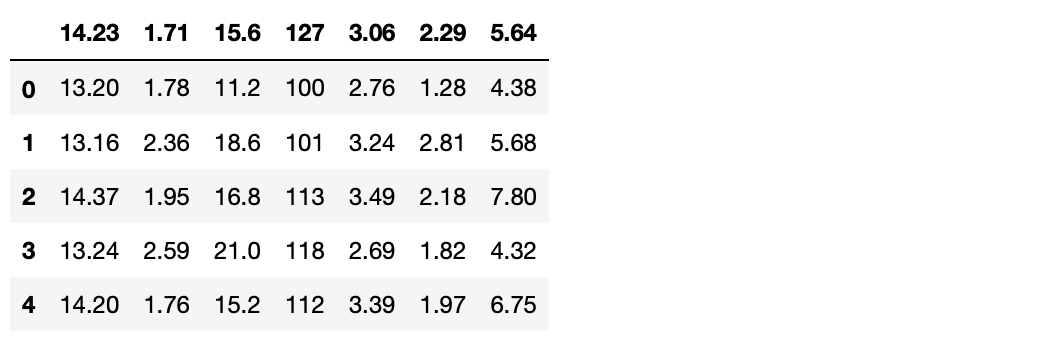
read_df = fdr.DataReader('SPY', '1993-01-29', '2023-09-12') # S&P 500 ETF 데이터를 가져옴.
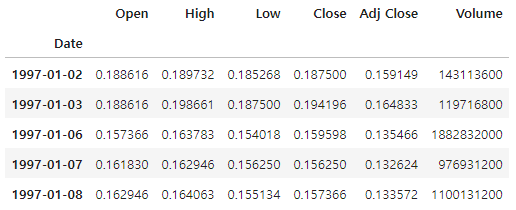
read_df.head()
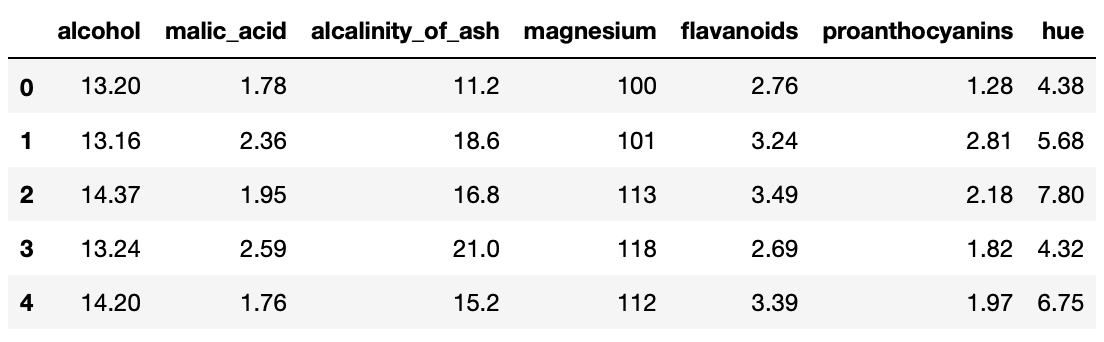
그 다음 조정 종가만 선택해 price_df 변수에 별도의 데이터프레임으로 저장한다.
price_df = read_df.loc[:,['Adj Close']].copy()
price_df.head()
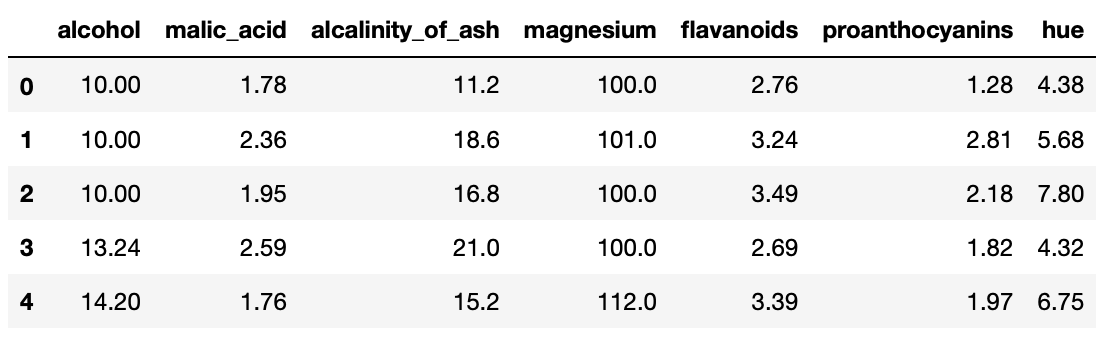
이 전략에서는 월말 데이터를 추가해서 사용한다.
price_df['STD_YM'] = price_df.index.to_period('M')
price_df.head()
이번에는 월말 종가에 접근하는 데이터프레임을 만들어 보자.
month_list = price_df['STD_YM'].unique()
month_last_df = pd.DataFrame()
for m in month_list:
# 기준 연월에 맞는 인덱스의 마지막 날짜 row를 데이터프레임에 추가
month_last_df = month_last_df._append(price_df.loc[price_df[price_df['STD_YM'] == m].index[-1], :])
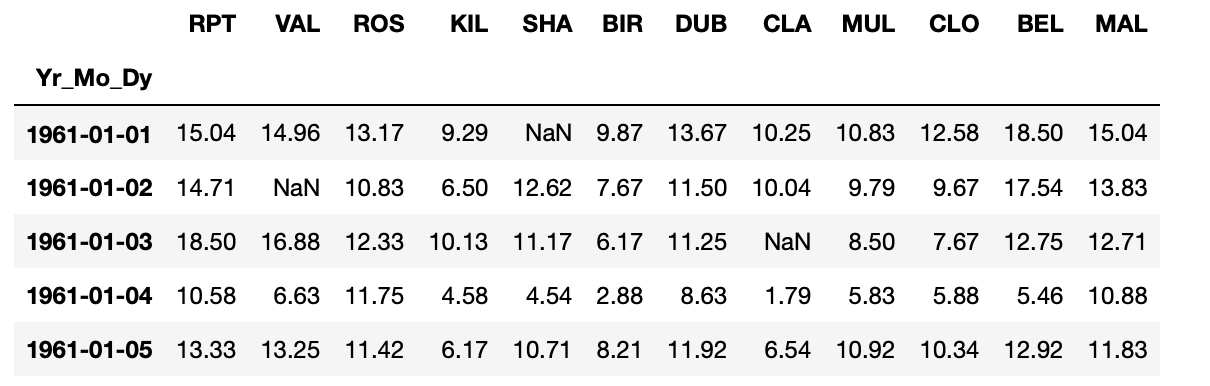
month_last_df.head()현재 데이터프레임에 있는 중복을 제거한 모든 '연-월' 데이터를 리스트에 저장해 월별 말일자에 해당하는 종가에 쉽게 접근할 수 있다.

월말 종가 데이터를 적재하는 별도의 데이터프레임을 만든다. 월말 종가 데이터 리스트를 순회하면서 index[-1]을 통해 월말에 쉽게 접근하고, 데이터를 추출해 새로 만든 데이터프레임에 적재한다.
(append가 pandas 2.0부터 제거됨. _append로 사용가능)
모멘텀 지수를 계산하기 위한 이전 시점의 데이터를 어떻게 가공하는지 살펴보자.
month_last_df['BF_1M_Adj Close'] = month_last_df.shift(1)['Adj Close']
month_last_df['BF_12M_Adj Close'] = month_last_df.shift(12)['Adj Close']
month_last_df.fillna(0, inplace=True)
month_last_df.head(15)
판다스 DataFrame에서 제공하는 shift()함수를 이용하면 손쉽게 데이터를 가공할 수 있다. shift() 함수는 기본값이 period = 1, axis = 0으로 설정되지만, 입력 매개변수를 원하는 값으로 대체해 사용할 수 있다.
우리가 만든 데이터프레임에서 1을 지정하면 1개월 전 말일자 종가를 가져오고, 12를 넣으면 12개월 전 말일자 종가 데이터를 가져오게 할 수 있다. 데이터를 뒤로 밀어내는 것인데 초기 n개의 행에는 값이 없으므로 np.nan 값이 출력된다.
이제 모멘텀 지수를 계산해서 거래가 생길 때 포지션을 기록할 DataFrame을 만든다.
book = price_df.copy()
book['trade'] = ''
book.head()
최종적으로 기록된 포지션을 바탕으로 최종 수익률을 계산하는 데 사용된다.
처음에 만든 일별 종가가 저장된 DataFrame을 복사해 날짜 Date 컬럼을 index로 설정하고 거래가 일어난 내역을 저장할 Trade 컬럼을 만든다.
# trading 부분
ticker = 'SPY'
for x in month_last_df.index:
signal = ''
# 절대 모멘텀을 계산
momentum_index = month_last_df.loc[x, 'BF_1M_Adj Close'] / month_last_df.loc[x,'BF_12M_Adj Close']-1
# 절대 모멘텀 지표 True/False를 판단
flag = True if ((momentum_index > 0.0) and (momentum_index != np.inf) and (momentum_index != -np.inf)) else False and True
if flag :
signal = 'buy ' + ticker # 절대 모멘텀 지표가 Positive이면 매수 후 보유
print('날짜 : ', x, '모멘텀 인덱스 : ', momentum_index, 'flag : ', flag, 'signal : ', signal)
book.loc[x:, 'trade'] = signal월별 인덱스를 순회하면서 12개월 전 종가 대비 1개월 전 종가 수익률이 얼마인지 계산한다. 계산된 수익률은 momentum_index 변수에 저장해 0 이상인지 확인하고, 0 이상이면 모멘텀 현상이 나타난 것으로 판단해 매수 신호가 발생하도록 한다. 이 부분을 flag 변수로 처리했다. 이어서 signal 변수에 저장된 매수 신호를 book 데이터프레임에 저장한다.
월말 종가를 기준으로 매수/매도 신호를 계산하므로 최소 1개월 이상 해당 포지션을 유지한다. 포지션을 유지하는 기간은 개인마다 다르지만 보통 1개월을 유지하기도 한다. 이를 전문 용어로 리밸런스 주기라고 한다.
그 다음으로 전략 수익률을 확인해 보자.
def returns(book, ticker):
# 손익 계산
rtn = 1.0
book['return'] = 1
buy = 0.0
sell = 0.0
for i in book.index:
if book.loc[i, 'trade'] == 'buy ' + ticker and book.shift(1).loc[i, 'trade'] == '' :
# long 진입
buy = book.loc[i, 'Adj Close']
print('진입일 : ', i, 'long 진입가격 : ', buy)
elif book.loc[i, 'trade'] == 'buy' + ticker and book.shift(1).loc[i, 'trade'] == 'buy ' + ticker:
# 보유중
current = book.loc[i, 'Adj Close']
rtn = (current - buy) / buy + 1
book.loc[i, 'return'] = rtn
elif book.loc[i, 'trade'] == '' and book.shift(1).loc[i, 'trade'] == 'buy ' + ticker:
# long 청산
sell = book.loc[i, 'Adj Close']
rtn = (sell - buy) / buy + 1 # 손익 계산
book.loc[i, 'return'] = rtn
print('청산일 : ', i, 'long 진입가격 : ', buy, ' | long 청산가격 : ', sell, ' | return: ', round(rtn, 4))
if book.loc[i, 'trade'] == '': # 제로 포지션
buy = 0.0
sell = 0.0
current = 0.0
acc_rtn = 1.0
for i in book.index :
if book.loc[i, 'trade'] == '' and book.shift(1).loc[i, 'trade'] == 'buy ' + ticker:
# long 청산시
rtn = book.loc[i, 'return']
acc_rtn = acc_rtn * rtn # 누적 수익률 계산
book.loc[i:, 'acc return'] = acc_rtn
print ('Accumulated return : ', round(acc_rtn, 4))
return (round(acc_rtn, 4))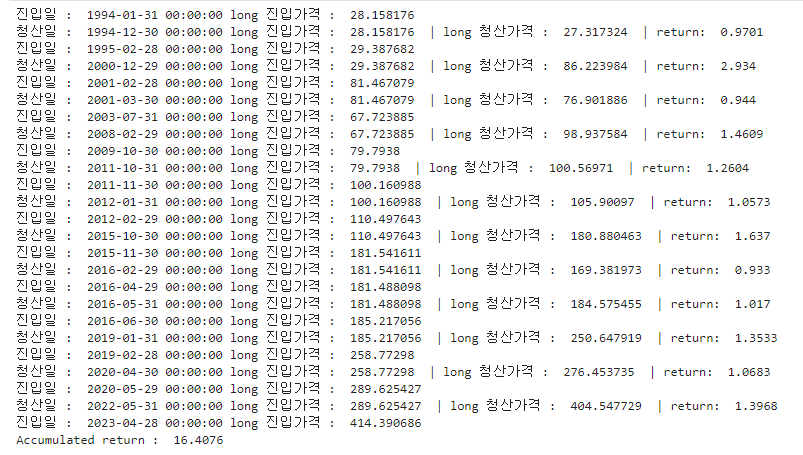
SPY ETF의 경우 12개월 전 대비 가격이 올랐을 때 매수하는 절대 모멘텀 전략의 수익률은 다음과 같다.
1에서 시작해 16.4076으로 종료되었으므로 1994년부터 2023년까지 1600%의 수익률을 낸 것이다.
지금까지 단일 종목을 절대 모멘텀 전략으로 구현해 보았다.
절대 모멘텀 전략은 종목별 자신의 과거 수익률을 기반으로 매수/매도 신호를 포착하므로 단일 종목으로도 구성할 수 있다.
<참고 서적> 퀀트 전략을 위한 인공지능 트레이딩
'파이썬으로 할 수 있는 일 > 실사용' 카테고리의 다른 글
| FinanceDataReader를 사용해 FRED 경기선행 지수 데이터 확인하기 (0) | 2023.10.25 |
|---|---|
| 파이썬으로 연습해보는 퀀트 투자 - 듀얼 모멘텀 중 상대 모멘텀 전략 (0) | 2023.09.19 |
| 파이썬으로 연습해보는 퀀트 투자 - 평균 회귀 전략 (0) | 2023.09.11 |
| 주피터 노트북(Jupyter Notebook) 서버 접속 및 실행 (0) | 2023.09.01 |
| Python WMS(Workflow Management System) 도구들 (1) | 2022.04.08 |