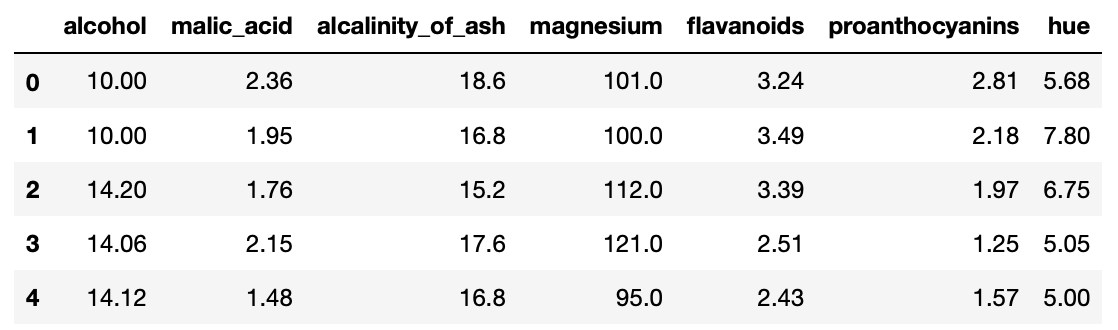
컴퓨터 비전이나 텍스트 분석은 성능 좋은 오픈 API나 노하우가 축적되고 공유되어 빠르게 발전하고 있다. 하지만 투자 업계에서는 금융 데이터를 손쉽게 처리해주는 판다스 같은 라이브러리가 있어도, 성능 좋은 알고리즘이나 방법론이 공유되는 경우가 거의 없다.
세계 경제가 긴밀하게 연동하고 경제 주체들의 투자 패턴이 다양해짐에 따라 고려해야 할 변수가 기하급수적으로 증가한 반면 시계열 데이터를 기본으로 한 투자 데이터는 그 양이 한정적이다. 애널리스트 분석에 자주 사용되는 OECD 경기선행지수, 국가별 GDP, 금리 자료 등은 업데이트 주기가 길다. 이러한 데이터의 한계로 인해 좋은 모델을 만들기가 어렵다고 한다.
금융은 자본주의 사회에서 우리의 삶에 깊숙이 침투하여 개인의 일상생활과 밀접한 관계를 맺고 있고 우리가 살아가며 생산하는 수많은 데이터를 통해 연결되어 있다. 많은 의사결정 프로세스가 데이터 기반으로 전환하는 시대에 투자라고 예외일 수 없다. 나날이 복잡다단해지는 투자 환경에서 사람의 '감'에 기반한 투자 의사결정은 점점 힘을 잃어갈 것이다.
투자 영역에서 활용하는 데이터('실전 금융 머신러닝 완벽분석'의 저자인 마르코스 로페즈가 분류)
재무제표 데이터
마켓 데이터
분석 데이터
대체 데이터
자산
가격/변동성
애널리스트 추천
위성/CCTV 이미지
부채
거래량
신용 등급
구글 검색어
판매량
배당
이익 예측
트윗/SNS
비용/이익
이자율
감성 분석
메타데이터
거시 변수
상장/폐지
...
...
파이썬으로 만드는 투자전략과 주요 지표
1. 바이앤홀드(Buy & Hold) 전략
바이앤홀드는 주식을 매수한 후 장기 보유하는 투자 전략이다. 즉 매수하려는 종목이 충분히 저가라고 판단될 때 주기적으로 매수한 후 장기간 보유하는 식으로 투자하는 방법이다. 주가는 예측이 불가하지만 경제가 성장함에 따라 장기적으로 우상향한다는 투자 철학의 관점에서 보면 합리적인 투자 방법이다.
주피터 노트북(Jupyter notebook) 환경에서 실행한다고 가정하고, 관련 라이브러리를 다음과 같이 설치해야 한다.
!pip install matplotlib
!pip install pandas
!pip install -U finance-datareader # 국내 금융데이터를 포함 pandas-datareader를 대체
준비가 되면, 관련 라이브러리를 불러온다
import pandas as pd
import numpy as np
import FinanceDataReader as fdr
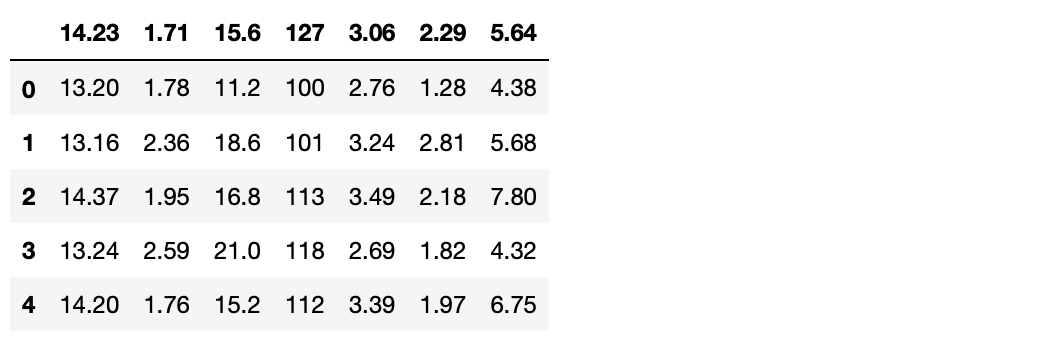
본격적으로 바이앤홀드 전략을 구현해 보자. FinanceDataReader 라이브러리에서 직접 테슬라(TSLA) 데이터를 추출하여, 판다스의 head()함수를 사용해 데이터를 살펴본다.
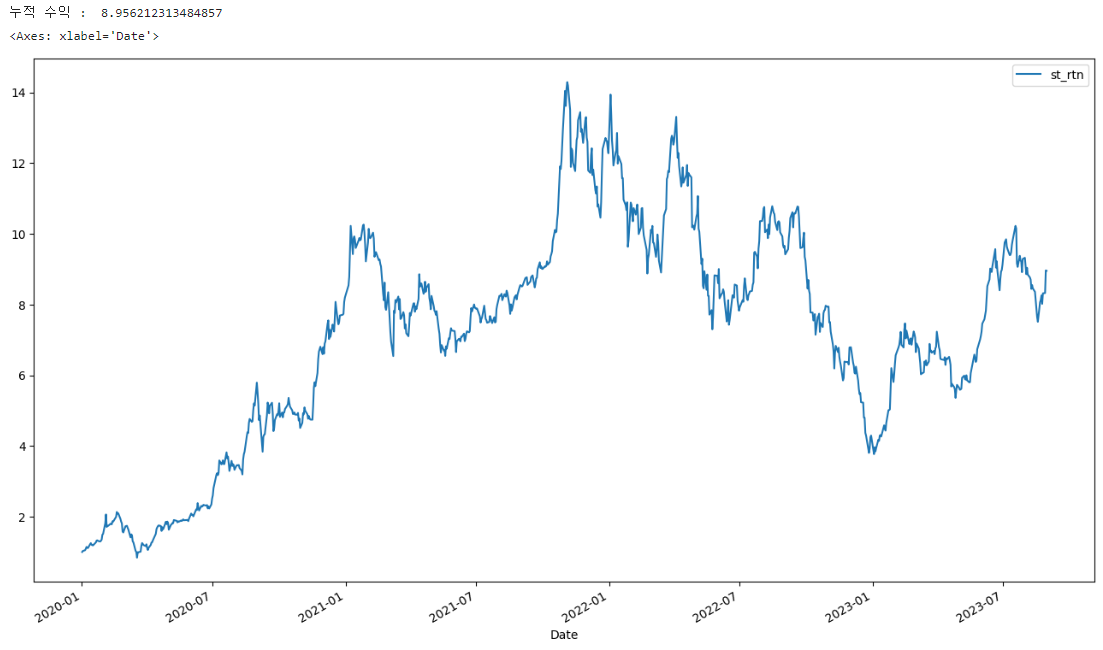
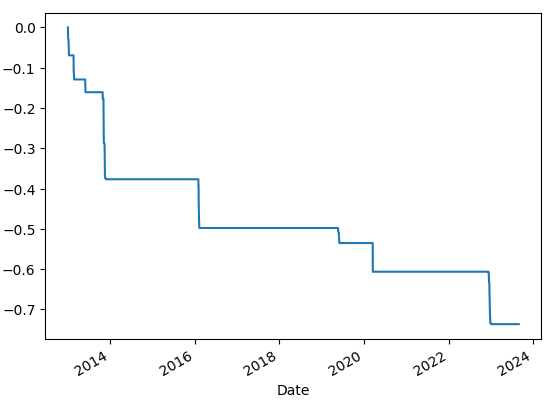
수정 종가(Adj Close)로 DataFrame을 만들고 종가(Close) 모양이 어떻게 생겼는지 그래프를 통해 살펴본다. 전체 기간을 보면 주가가 많이 상승했다. 하지만 짧은 시점을 확인해 보면 다를 수 있다. 테슬라는 최근 2022~2023년에 주가 변동성이 매우 큰 것을 알 수 있다.
우리가 가진 데이터셋의 마지막 날짜가 2023년 8월 30일이다. 해당일자의 최종 누적 수익률의 누적 연도 제곱근을 구하는 것이다. 또한 우리는 일(Daily) 데이터를 사용했으므로 전체년도를 구하기 위해 전체 데이터 기간을 252(금융공학에서 1년은 252 영업일로 계산)로 나눈 역수를 제곱(a**b) 연산한다. 그리고 -1을 하면 수익률이 나온다.
- 최대 낙폭(MDD)
최대 낙폭은 최대 낙폭 지수로, 투자 기간에 고점부터 저점까지 떨어진 낙폭 중 최댓값을 의미한다. 이는 투자자가 겪을 수 있는 최대 고통을 측정하는 지표로 사용되며, 낮을수록 좋다.
수정 종가에 cummax() 함수 값을 저장한다. cummax()는 누적 최댓값을 반환한다. 전체 최댓값이 아닌 행row별 차례로 진행함녀서 누적 값을 갱신한다. 현재 수정 종가에서 누적 최댓값 대비 낙폭률을 계산하고 cummin() 함수를 사용해 최대 하락률을 계산한다. 출력 그래프를 보면 최대 하락률의 추세를 확인할 수 있다.
- 변동성(Vol)
주가 변화 수익률 관점의 변동성을 알아보자. 변동성은 금융 자산의 방향성에 대한 불확실성과 가격 등락에 대한 위험 예상 지표로 해석하며, 수익률의 표준 편차를 변동성으로 계산한다.
만약 영업일 기준이 1년에 252일이고 일별 수익률의 표준 편차가 0.01이라면, 연율화된 변동성은 다음 수식과 같이 계산된다.
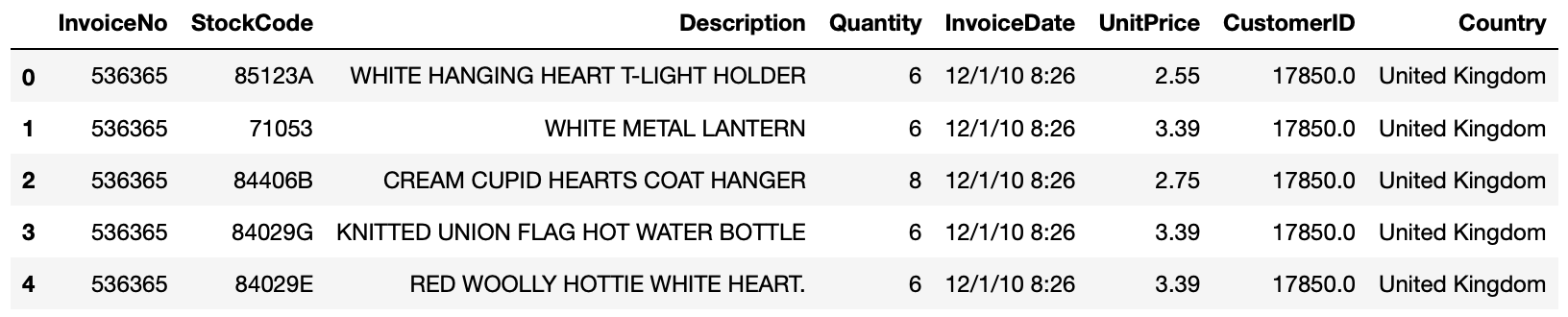
>>> online_rt = pd.read_csv(path, encoding = 'latin1') # encoding 인수로 적합한 언어 인코딩을 적용합니다.
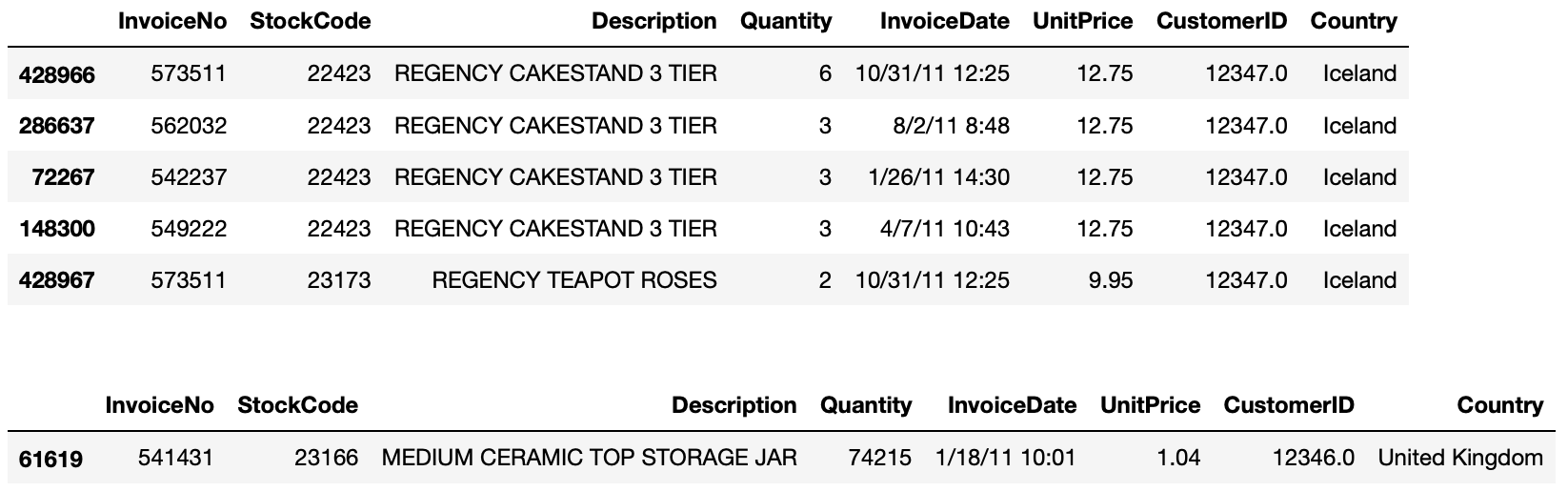
>>> online_rt.head()
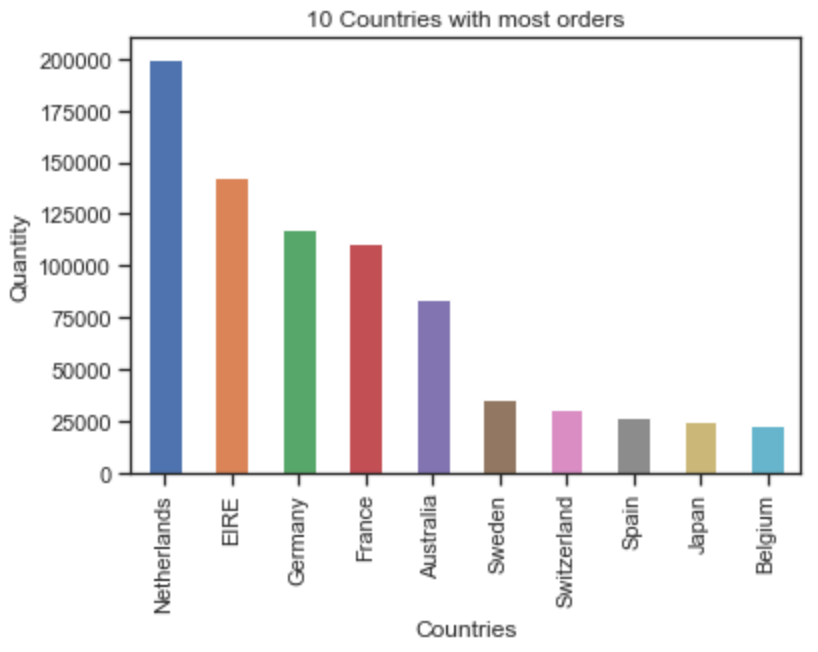
4. 영국을 제외하고 수량(Quantity)이 가장 많은 10개 국가에 대한 히스토그램을 만듭니다.
>>> countries = online_rt.groupby('Country').sum() # groupby 메서드를 사용해 국가별 합계를 구하고 countries 변수에 저장합니다.
>>> countries = countries.sort_values(by = 'Quantity', ascending=False) # sort_values 메서드로 정렬합니다. 이때 정렬 기준은 by인수를 사용해 'Quantity'로 정하고, ascending=False를 사용해 내림차순으로 정리합니다.
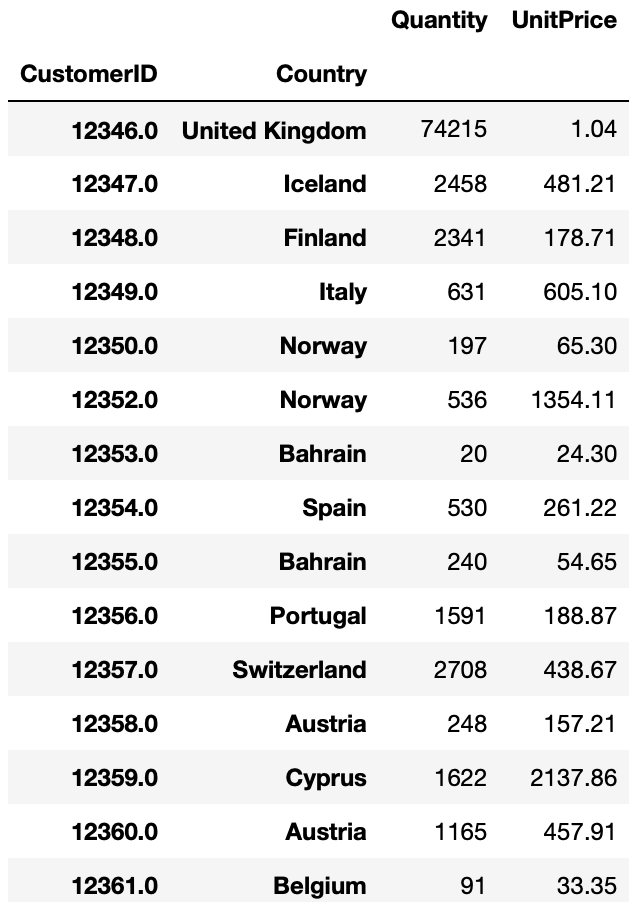
>>> display(online_rt[online_rt.CustomerID == 12346.0].sort_values(by='UnitPrice', ascending=False).head()) # 고객ID 12346.0번은 다른 나라와 다르게 수량이 매우 많고, 단가는 매우 낮게 나옵니다. 그 이유를 알아볼 필요가 있어서 살펴보고자 합니다. 아래 데이터에서 보듯이 고객 ID 12346.0은 단 한건의 주문으로 대량 주문한 경우가 되겠습니다.
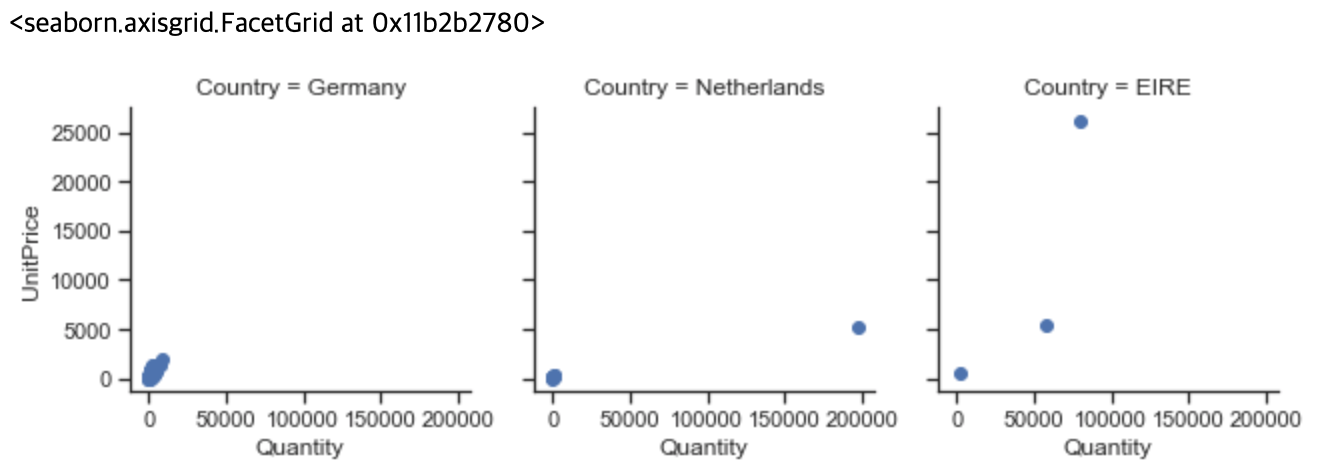
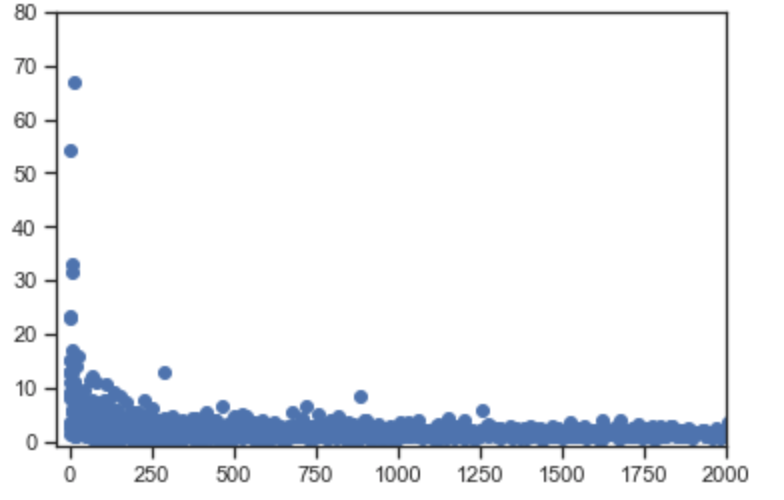
7-2. 6번 최초의 질문으로 돌아가 보면, '상위 3개 국가의 고객 ID별 단가별 수량을 사용하여 산점도를 만듭니다'에 대해 구체화해서 생각해 봐야 합니다. 총 판매량이냐? 아니면 총 수익으로 계산해야 할 것인가? 먼저 판매량에 따라 분석해 보도록 하겠습니다.
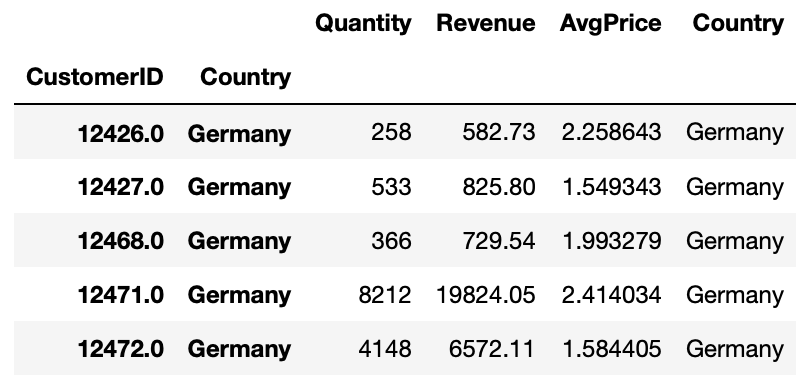
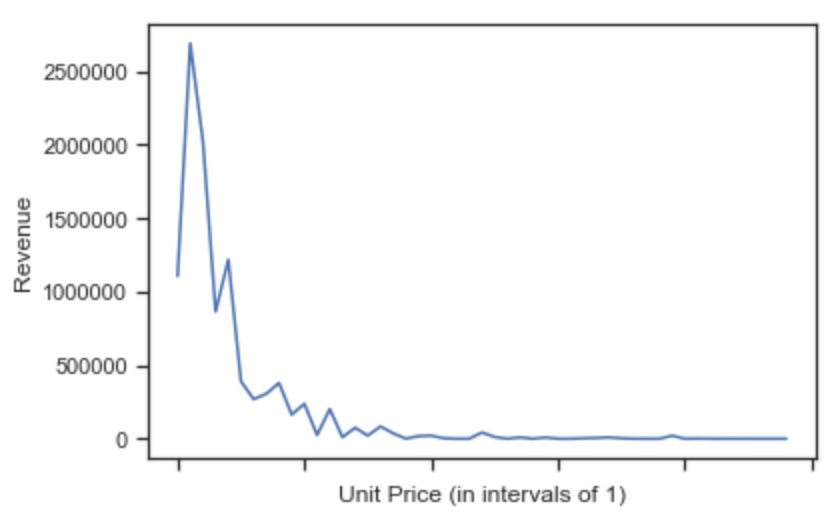
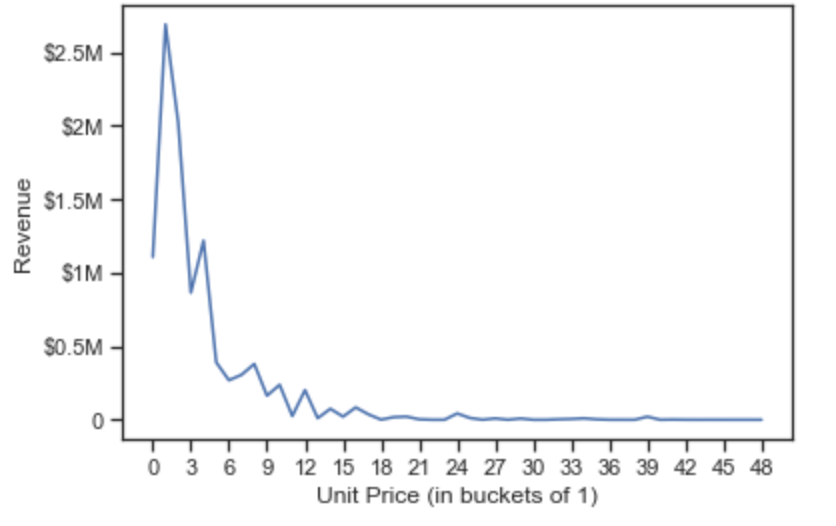
7-3. 이제 상위 3개국을 알게 되었습니다. 이제 나머지 문제에 집중합니다. 국가 ID는 쉽습니다. groupby 메서드로 'CustomerID'컬럼을 그룹핑하면 됩니다. 'Quantity per UnitPrice'부분이 까다롭습니다. 단순히 Quantity 또는 UnitPrice로 계산하는 것은 원하는 단가별 수량을 얻기 어렵습니다. 따라서, 두개 컬럼을 곱해 수익 'Revenue'라는 컬럼을 만듭니다.
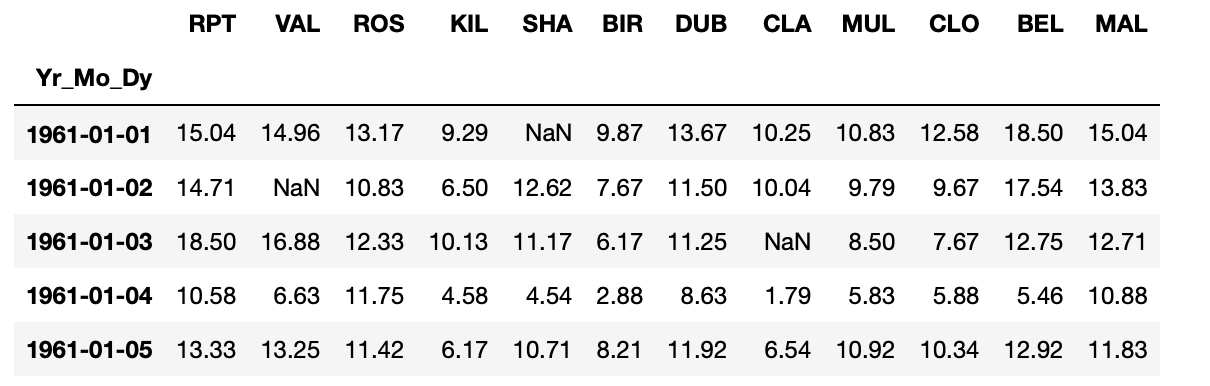
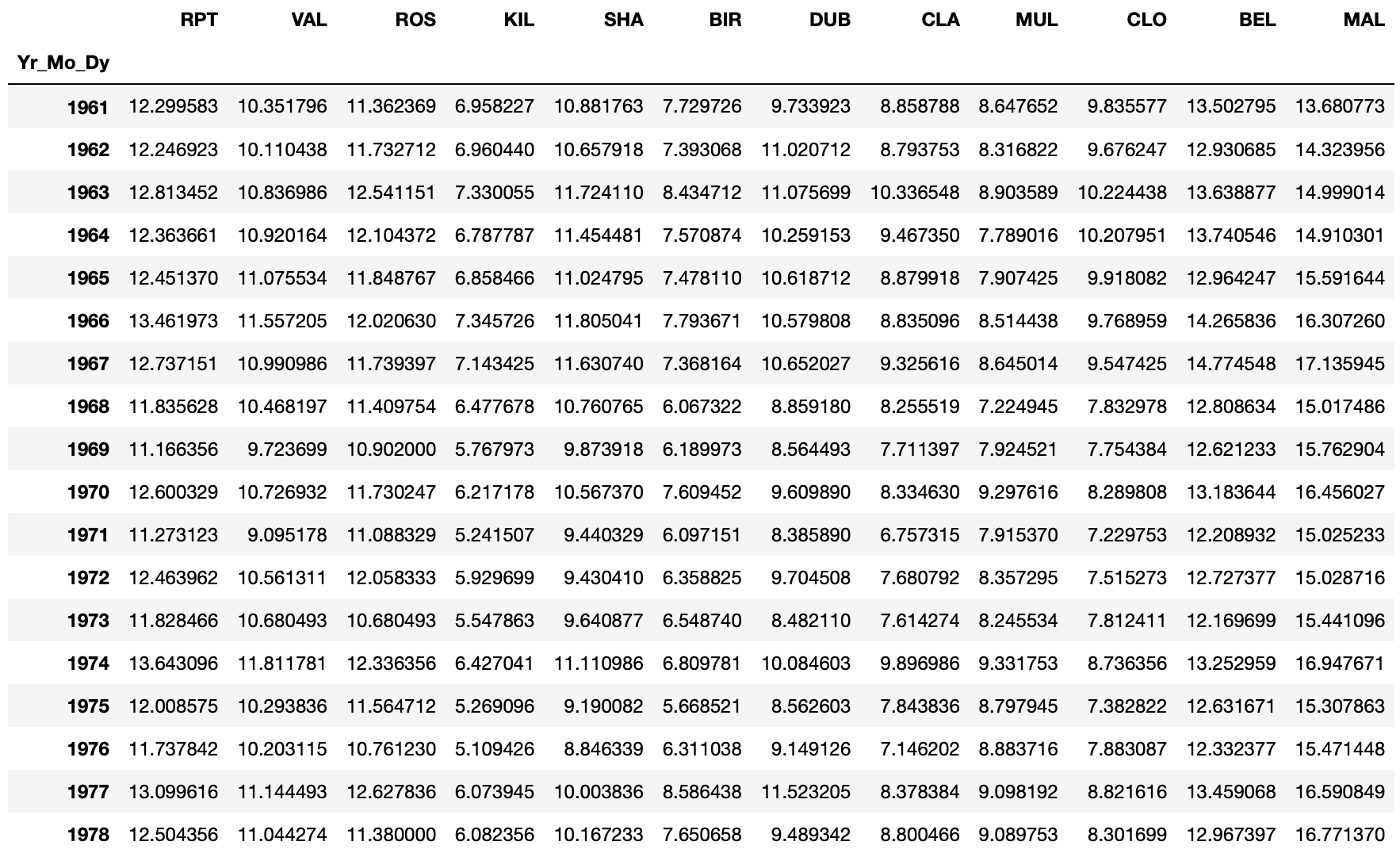
3. pandas로 위 주소를 data 변수로 읽어들이되, 처음 3개 컬럼을 datetime 인덱스로 대체합니다.
>>> data = pd.read_table(data_url, sep = '\s+', parse_dates = [[0, 1, 2]]) # parse_dates 인수는 불린값 또는 숫자 리스트 또는 여러 컬럼들 값을 읽어들여서 날짜로 처리할 수 있습니다. 여기서는 맨 앞에 3개의 컬럼 값으로 날짜를 인식하도록 합니다.
>>> data.head() # 데이터셋의 구조를 알아보기 위해 상위 열 5개를 조회합니다.
4. 년도가 2061? 이 년도의 데이터가 실제로 있을까요? 이것을 수정해서 적용할 수 있는 함수를 만들어 봅시다.
>>> def fix_century(x): year = x.year - 100 if x.year > 1989 else x.year return datetime.date(year, x.month, x.day) # 년도 데이터를 1900년대와 2000년대 구분을 위해 1989보다 많은 경우에는 1900년대으로 변경하도록 if문으로 간단한 함수를 만듭니다.
>>> data['Yr_Mo_Dy'] = data['Yr_Mo_Dy'].apply(fix_century) # apply 메서드를 사용해 'Yr_Mo_Dy'] 컬럼 전체에 함수를 적용합니다.
>>> data.head() # 다시 데이터셋의 구조를 알아보기 위해 상위 열 5개를 조회합니다.
5. 날짜를 인덱스로 설정합니다. 이때 데이터 타입을 변경해서 적용해야 합니다. 데이터 타입은 datetime64[ns]여야 합니다.
>>> pd.merge(all_data, data3, on='subject_id') # on 인수를 통해 기준열을 명시했습니다
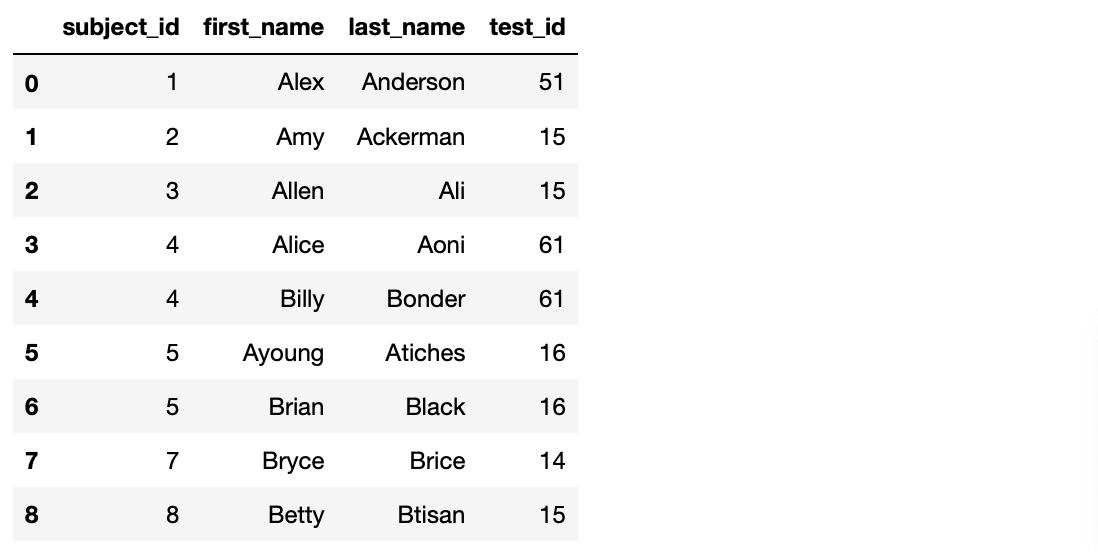
8. data1과 data2에 동일한 'subject_id'가 있는 데이터만 병합합니다.
>>> pd.merge(data1, data2, on='subject_id', how='inner') # how 인수를 통해 양쪽 데이터프레임 모두 키가 존재하는 데이터만 보여줍니다. how 인수로 명시하지 않아도 기본적으로 'inner'를 적용한 것으로 처리하기 때문에 양쪽 모두 존재하는 데이터만 보여줍니다.
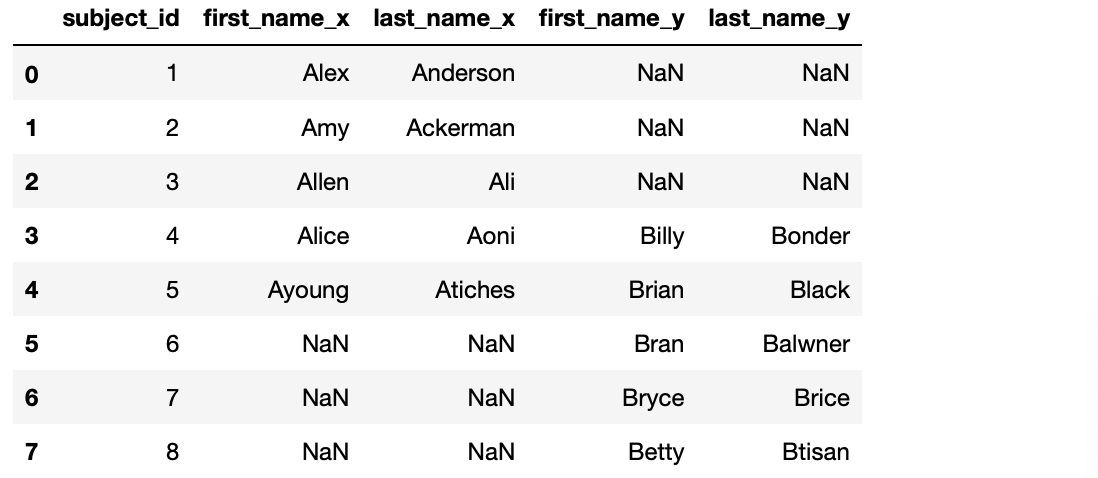
9. data1과 data2의 키 값이 한쪽에만 있더라도 모든 값들을 병합합니다.
>>> pd.merge(data1, data2, on='subject_id', how='outer') # 값이 없는 필드에는 NaN(Null 값)으로 표시합니다.