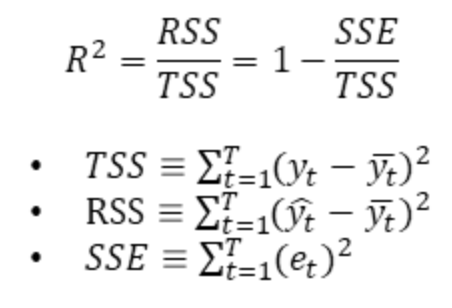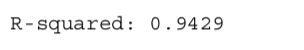아직 나에겐 젊은 나이인 32살, 드로우앤드류의 책 '럭키 드로우'를 사서 읽어 보았다. 멋진 청년이고 적극적인 성격과 성공해본 경험을 소유한 친구였다. 어린 나이가 부럽고 두려움을 극복하고 자신이 원하는 일을 하면서 살아가는 모습에 시기심마저 생겼다. 그렇다고 내가 감당하지 못할 정도의 시기심은 아니고, 나를 자극하는 그런 시기심?이라고 해야하나...
앤드류의 글과 유튜브를 보면서 내가 젊다고 생각해 왔으나, 나도 모르게 마음이 쫄아 들어왔구나 라는 깨달음 같지 않은 나만의 깨달음이 생겼다. 나는 그 동안 직장에 안주하면서도 나름 나의 가치를 높히기 위해 저녁시간을 활용하거나 또 다른 업을 만들기 위해 노력해 왔고, 어느 정도는 만족할만한 수준에 이르렀다고 생각해 왔다. 하지만, 가장 중요한 부분을 놓치고 있는 것을 알게 되었다. 앞으로 살아가는데 필요한 어느 정도의 재력은 갖게 되었지만, 내가 원하는 일을 하면서 살 수 있는 삶은 아니었다. 새로운 일이나 세상을 변화를 외면하고, 지금 있는 곳에 안주하고 도전을 꺼려하는 모습으로 변해왔다는 말이다.
시도하는 것이 중요하다는 것을 다시 한번 알려줘서 고맙다. 막연한 두려움, 완벽함에 대한 추구 등이 나를 주저하게 하고 실행하는 것을 막는다. 이제는 다시 습관을 만들어야할 시기라고 생각한다. 시도하면서 알아가는 일, 날 성장시키는 일을 다시 시작해야지. 늙는다는 것은 물리적인 나이의 문제라기 보다는 마음의 문제라고 봐야겠다. 돈을 버는 것보다 어떤 새로운 일, 작업을 하면서 만족할 수 있는지에 대한 도전을 하는 마음을 일깨워준 글이었다.
앤드류의 젊음이 매우 부럽지만, 흘러간 시간을 아쉬워만 하는 것은 무의미할 것이다. 나도 앞으로 30~40년을 더 살 수 있다고 보기에 남은 나의 여정을 후회없이 보낼 수 있도록 하루 하루 최선을 다해 살아나가자.
1. 자연어 처리(Natural Language Processing, NLP) : 자연어 처리(NLP)는 인간이 대화하는 말의 형태를 기계가 배우는 머신러닝 방법을 말한다. 지금까지 기본적으로 NLP로 진행해 왔던 분류는 다음과 같다. - 텍스트 분류 및 순위(Text classification and ranking) : 스팸이나 정크 메일을 필터링 해서 분류하는 것이 대표적이다. - 감성 분석(Sentiment analysis) : 이 분석은 머신이 제공하는 피드백에 대한 감성적 반응을 예측한다. 고객 관계와 만족도가 팩터가 된다. - 문서 요약(Document summarization) : 복합적이고 복잡한 긴 글을 짧고 압축된 정의를 사용해 제시하는 방법이다. 궁극적인 목적은 이해하기 쉽게 만드는데 있다. - 개체 이름 인식(Named-Entity Recognition, NER) : 이것은 비구조화된 언어들 세트에서 구조화되고 인식가능한 데이터를 찾아내는 것이다. 이 머신러닝 프로세스는 대화 중 문맥에 맞게 적용하거나 가장 적합한 반응을 이끌어내는데, 가장 적합한 키워드를 알아내는 것을 배운다. - 음성 인식(Speech recognition) : 음성 인식은 아마존 알렉사, 구글 어시스턴트 등에서 쉽게 볼 수 있는 메커니즘이다. 이 메커니즘의 기본은 사람의 음성으로부터 오디오 신호를 인식하여 활자와 결합하는 것을 배우는 것이다. - 기계 번역(Machine translation) : 기록된 특정 나라 언어를 다른 나라의 언어로 변환하는 자동화된 시스템을 말한다.
반응형
2. 데이터셋(Dataset) : 머신러닝의 실행 가능성과 진행을 테스트하기 위해 사용할 수 있는 변수들의 집합이라고 할 수 있다. 데이터는 머신러닝을 진행하기 위한 필수 요소이다. - 트레이닝 데이터(Training data) : 이름에서 알 수 있듯이, 트레이닝 데이터는 추론을 통한 모델 학습을 통해 패턴을 예측하기 위해 사용된다. 트레이닝 데이터의 영향력이 매우 크기 때문에, 다른 요소에 비해 매우 중요한 요소라 할 수 있다. - 검증 데이터(Validation data) : 트레이닝된 모델의 하이퍼 파라미터를 미세 조정하는데 사용하는 데이터이다. 이를 통해 최종 완성된 모델이 만들어진다. - 테스트 데이터(Test data) : 모델 학습이 완성되었다고 생각되면, 테스트 데이터를 통해 완성된 모델이 실제 제대로 동작하는지 확인한다.
3. 컴퓨터 비전(Computer Vision, CV) : 이미지와 영상 데이터에 대한 고급 분석을 제공하는 툴이라고 할 수 있다. - 이미지 분류(Image classification) : 다양한 이미지와 그림 표현을 인식하고 학습하도록 한다. 이 모델은 색상 변경과 같은 작은 변화가 있는 동일한 이미지를 인식하여 동일한 이미지로 유지한다. - 객체 인식(Object detection) : 이미지 분류와 달리, 전체 뷰에서 객체 이미지를 인식하는데 사용되는 모델이다. 이 모델은 대용량 데이터 셋에 객체 식별을 적용할 수 있고, 패턴 인식이 가능하도록 해준다. - 이미지 분할(Image segmentation) : 이 모델은 과거에 처리한 픽셀과 특정 이미지 또는 영상 픽셀을 연결하는 것이다. - 특징 인식(Saliency detection) : 이미지 또는 영상 속에서 시각적으로 가장 중요한 물체가 어디에 있는지 얼마나 중요한지 찾아내기 위한 모델이다. * Object detection은 영상 속 존재하는 모든 물체들의 위치를 box형태로 찾아내고 각각의 종류를 분류하는 것이고, Object segmenatation은 영상을 같은 종류 물체끼리 분할하여 픽셀 단위로 표시하는 것이다. Saliency detection은 이미지 내에서 중요하다고 생각되는 물체를 검출해내는 방법과 사람의 시선이 어디에 가장 오래 머물지 예측하는 방법으로 나뉜다.
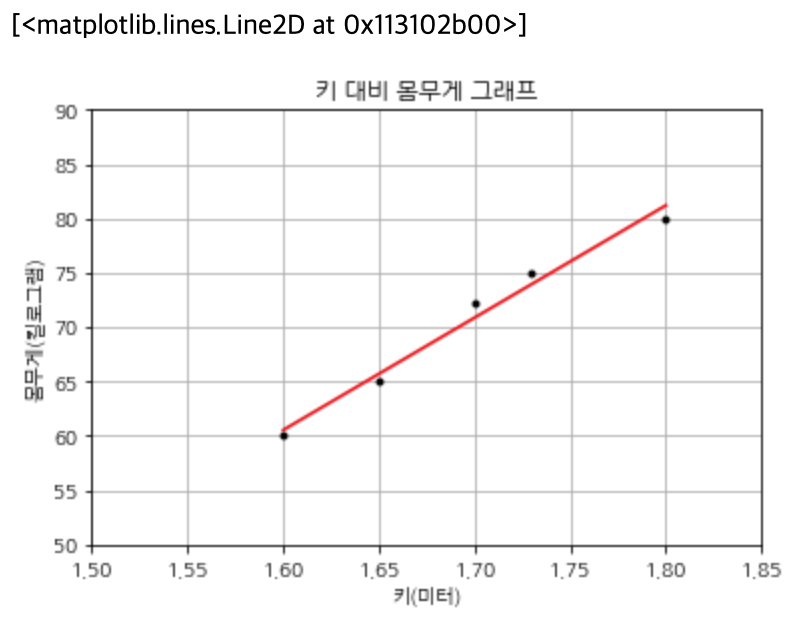
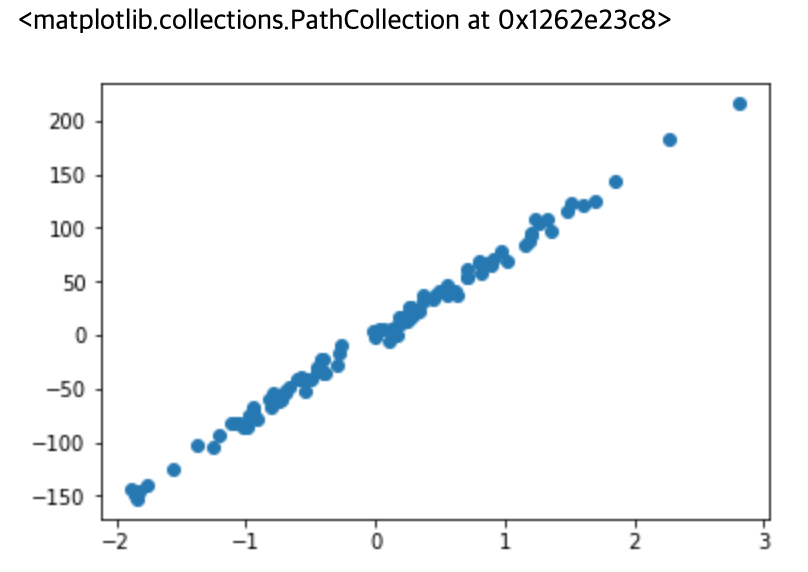
그래프에서 볼 수 있듯이, 사람들의 몸무게와 키 사이에는 양의 상관관계가 있다는 것을 알 수 있습니다.
위 그래프에서 점을 기반으로 직선을 그리고, 그 직선으로 키에 따른 다른 사람의 몸무게를 예측할 수 있습니다.
모델 피팅을 위한 LinearRegression 클래스 사용하기
그렇다면 모든 점들을 연결해서 중심축을 지나는 직선을 어떻게 그릴 수 있을까요? 이를 수행하기 위해 사이킷런(Scikit-learn) 라이브러리에는 LinearRegression 클래스가 있습니다. 우리가 해야 하는 일은 이 클래스의 인스턴스를 만들고, 몸무게와 키의 리스트를 사용해 fit() 함수로 다음과 같이 선형 회귀분석(linear regression) 모델을 생성하는 것입니다.
>>> from sklearn.linear_model import LinearRegression
>>> model = LinearRegression() # 모델을 생성합니다.
>>> model.fit(X=heights, y=weights) # 모델에 X, y 값들을 적용합니다. fit 함수는 리스트 또는 배열 형태의 X, y 인수들을 필요로 합니다.
반응형
예측 만들기
fit 함수로 모델을 훈련하고 나면, predict 함수를 사용해 다음과 같이 예측을 만들 수 있습니다.
>>> weight = model.predict([[1.75]])[0][0]
>>> round(weight, 2) # 예측 값은 76.04로 나옵니다.
위 예제에서, 훈련된 모델을 기반으로 키가 1.75m인 사람의 몸무게는 76.04kg으로 예측되었습니다.
선형 회귀분석 선 그리기
LinearRegression 클래스에 의해 생성된 선형 회귀분석 선을 시각화하는 것이 유용할 것입니다. 먼저 원래의 데이터 포인트를 플로팅한 다음 모델에 키 목록을 보내 가중치를 예측합니다. 그런 다음 일련의 예상 가중치를 플롯하여 선을 얻습니다. 다음 스니펫 코드는 수행되는 방식을 보여줍니다.
>>> import matplotlib.pyplot as plt
>>> plt.rc('font', family='NanumGothic') # 한글을 표시하기 위해, 한글 폰트를 설정합니다. 여기서는 네이버 글꼴로 처리했습니다. 무료로 지원되는 네이버 글꼴을 미리 다운로드 받아야 합니다. 다른 글꼴을 사용하시려면 글꼴명을 변경해서 사용하시면 됩니다.
>>> plt.plot(heights, model.predict(heights), color='r') # 선형 회귀 선을 그립니다.
선형 회귀분석 선의 기울기 및 절편 얻기
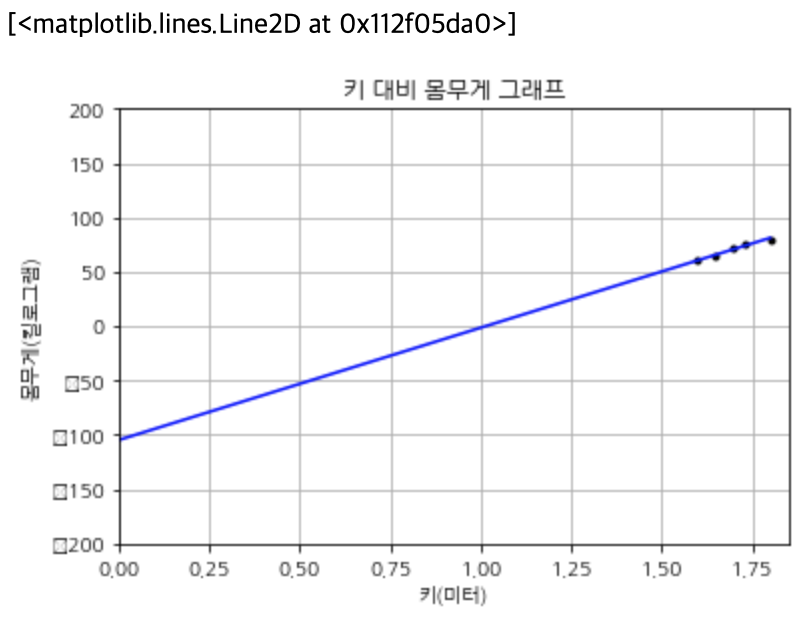
위 그래프에서는 선형 회귀분석 선의 y 축 절편이 무엇인지 명확하지 않습니다. 이는 1.5로 플로팅을 시작하도록 x축을 조정했기 때문입니다. 이를 시각화하는 더 좋은 방법은 x 축을 0에서 시작하고 y 축의 범위를 확대하여 설정하는 것입니다. 그런 다음 높이 0과 1.8의 두 가지 극단 값을 입력하여 선을 그립니다. 다음 스니펫 코드는 점과 선형 회귀분석 선을 다시 그립니다.
>>> plt.title('키 대비 몸무게 그래프')
>>> plt.xlabel('키(미터)')
>>> plt.ylabel('몸무게(킬로그램)')
>>> plt.plot(heights, weights, 'k.')
>>> plt.axis([0, 1.85, -200, 200])
>>> plt.grid(True)
>>> extreme_heights = [[0], [1.8]]
>>> plt.plot(extreme_heights, model.predict(extreme_heights), color='b') # 선형 회귀분석 선을 그립니다.
>>> round(model.predict([[0]])[0][0], 2) # 키가 0 인 경우 몸무게를 예측하여 y 절편(-104.75)을 얻을 수 있습니다.
>>> round(model.intercept_[0], 2) # intercept_ 속성을 통해 직접 답변(-104.75)을 받을 수 있습니다.
>>> round(model.coef_[0] [0], 2) # coef_ 속성을 통해 선형 회귀 선의 그래디언트(103.31)을 얻을 수도 있습니다.
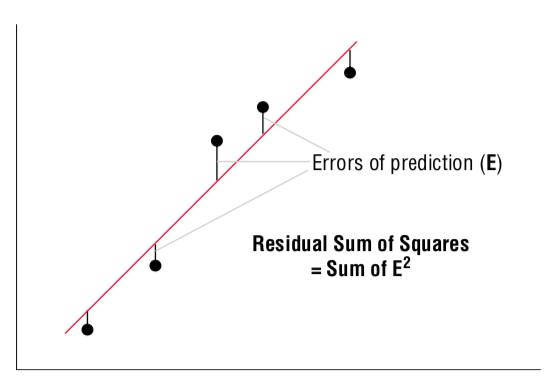
RSS를 계산하여 모델의 성능 검토하기
선형 회귀분석 선이 모든 데이터 요소가 잘 맞는지 알아 보려면, RSS(Residual Sum of Squares) 메서드를 사용합니다.
먼저 이와 관련된 용어들에 대해 알아보도록 하겠습니다.
R-squared(R^2)는 우리말로 결정계수라고 합니다.
R-squared는 0부터 1 사이의 값을 가지고, 1에 가까울수록 설명력이 높은 것을 의미합니다(선형 회귀분석 모델이 얼마나 데이터를 잘 설명해 주는지에 대한 값입니다)
Scikit-learn 라이브러리는 파이썬에서 가장 유명한 머신러닝 라이브러리 중 하나로, 분류(classification), 회귀(regression), 군집화(clustering), 의사결정 트리(decision tree) 등의 다양한 머신러닝 알고리즘을 적용할 수 있는 함수들을 제공합니다.
이번에는 머신러닝 수행 방법을 알아보기 전에, 다양한 샘플 데이터를 확보할 수 있는 방법들을 알아보려고 합니다.
데이터셋(Datasets) 얻기
머신러닝을 시작할 때, 간단하게 데이터셋을 얻어서 알고리즘을 테스트해 보는 것이 머신러닝을 이해하는데 있어 매우 유용합니다. 간단한 데이터셋으로 원리를 이해한 후, 실제 생활에서 얻을 수 있는 더 큰 데이터셋을 가지고 작업하는 것이 좋습니다.
우선 머신러닝을 연습하기 위해, 간단한 데이터셋을 얻을 수 있는 곳은 다음과 같습니다. 하나씩 차례대로 알아보도록 하겠습니다.
사이킷런의 빌트인 데이터셋
캐글(Kaggle) 데이터셋
UCI(캘리포니아 대학, 얼바인) 머신러닝 저장소
<사이킷런 데이터셋 사용하기>
사이킷런에는 머신러닝을 쉽게 배울 수 있도록 하기 위해, 샘플 데이터셋을 가지고 있습니다.
샘플 데이터셋을 로드하기 위해, 데이터셋 모듈을 읽어들입니다. 다음은 Iris 데이터셋을 로드한 코드입니다.
>>> from sklearn import datasets
>>> iris = datasets.load_iris() # 아이리스 꽃 데이터셋 또는 피셔 아이리스 데이터셋은 영국의 통계 학자이자 생물학자인 로널드 피셔 (Ronald Fisher)가 소개한 다변수 데이터셋입니다. 데이터셋은 3종의 아이리스(Iris)로 된 50개 샘플로 구성되어 있습니다. 각 샘플로부터 4개의 피쳐(features:피쳐를 우리말로 변수 또는 요인이라고 표현하기도 함)를 측정할 수 있습니다: 꽃받침과 꽃잎의 길이와 너비입니다. 이러한 4가지 피쳐(features)의 결합을 바탕으로 피셔는 종을 서로 구분할 수 있는 선형 판별 모델을 개발했습니다.
로드된 데이터셋은 속성-스타일 접근을 제공하는 파이썬 딕셔너리, 번치(bunch) 객체로 표현됩니다.
>>> print(iris.DESCR) # DESCR 속성을 사용해 데이터셋의 정보를 다음과 같이 얻을 수 있습니다.
>>> print(iris.data) # data 속성을 사용해 피쳐를 알아볼 수 있습니다.
>>> print(iris.feature_names) # feature_names 속성으로 피쳐 이름을 알아낼 수 있습니다.
이것은 데이터셋이 꽃받침 길이, 꽃받침 너비, 꽃잎 길이, 꽃잎 너비 등 4개의 컬럼들로 구성되어 있다는 것을 의미합니다.
꽃의 꽃잎(petal)과 꽃받침(sepal)
>>> print(iris.target) # 레이블을 알 수 있습니다.
>>> print(iris.target_names) # 레이블 이름을 알 수 있습니다.
여기서 0은 'setosa'를, 1은 'versicolor'를 2는 'virginica'를 나타냅니다.
(사이킷런의 모든 샘플 데이터가 feature_names, target_names 속성을 지원하는 것은 아닙니다)
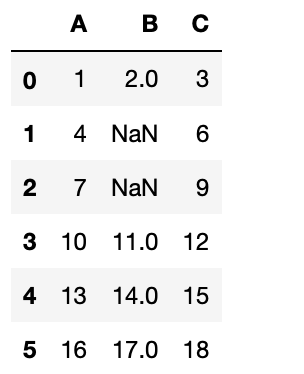
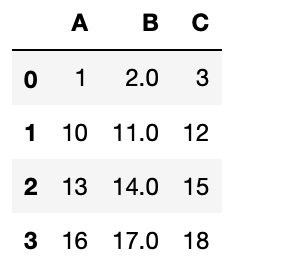
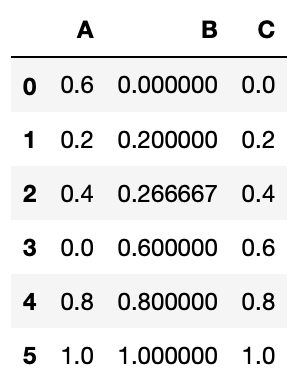
여기서, 데이터를 쉽게 다루기 위해, 판다스(Pandas)의 데이터프레임으로 변환하는 것이 유용합니다.
>>> import pandas as pd # pandas 라이브러리를 읽어들입니다.
>>> df = pd.DataFrame(iris.data)
>>> df.head()
<캐글(Kaggle) 데이터셋 사용하기>
데이터 과학자 및 머신러닝 학습자들에게 있어,캐글(Kaggle)은 세계에서 가장 큰 커뮤니티입니다.
머신러닝 경쟁을 제공하는 플랫폼에서 시작하여, 현재 캐글(Kaggle)은 공개 데이터 플랫폼과 데이터 과학자를 위한 클라우드 기반 워크 벤치도 제공합니다.
구글이 2017년 3월에 캐글(Kaggle)을 인수했습니다.
우리는 머신러닝 학습자들을 위해, 캐글(Kaggle)에서 제공된 샘플 데이터셋을 이용할 수 있습니다.