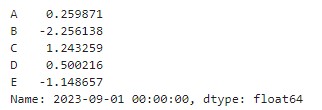
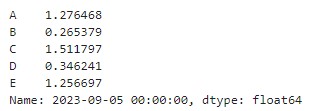
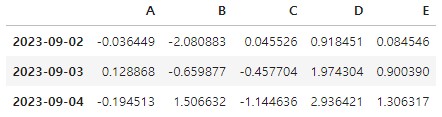
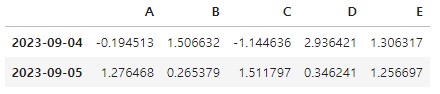
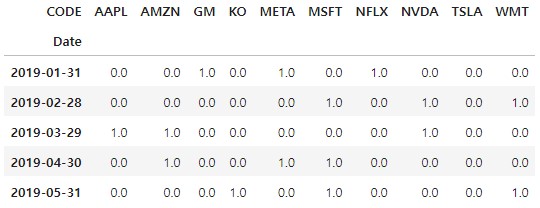
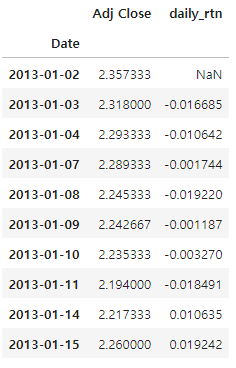
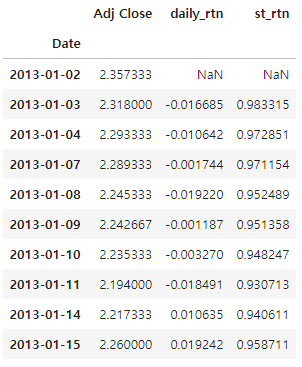
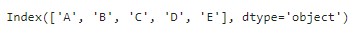월별 수익률이 행으로 쌓여있는 데이터를 피벗해 일자별로 종목별 수익률 데이터로 만든다. 종목 코드를 컬럼으로 올리고, DataFrame의 rank()함수를 사용해 월말 수익률의 순위를 퍼센트 순위로 계산하고 상위 40% 종목만 선별한 다음 나머지 값에는 np.nan값을 채운다.
월말일자로 1로 표시된 종목코드와 0으로 표시된 종목코드를 확인할 수 있다. 다음 날짜로 넘어갈 때 0에서 1로 되면 제로 포지션에서 매수 포지션으로 변경되고 1에서 0으로 변경되면 청산한다. 1에서 1로 변함없는 종목은 매수후 보유상태를 유지한다.
반응형
다음에 진행할 순서는 월말에 거래 신호가 나타난 종목을 대상으로 포지셔닝을 처리하는 것이다.
sig_dict = dict()
# 신호가 포착된 종목 코드만 읽어오기
for date in month_ret_df.index:
ticker_list = list(month_ret_df.loc[date, month_ret_df.loc[date,:] >= 1.0].index)
sig_dict[date] = ticker_list
stock_c_matrix = stock_df.pivot_table(index='Date', columns='CODE', values='Adj Close').copy()
book = create_trade_book(stock_c_matrix, list(stock_df['CODE'].unique()))
for date, values in sig_dict.items(): # 포지셔닝
for stock in values:
book.loc[date,'p '+ stock] = 'ready ' + stock
book = tradings(book, stock_codes) # 트레이딩
신호가 발생한 종목 리스트를 만들고 stock_df 변수를 피벗해 만든 stock_c_matrix 변수를 전달해 새로운 거래 장부 역할 변수를 만든다.
거래 장부 역할 변수는 다음의 코드로 작성된 create_trade_book() 함수로 만들어진다.
그 다음 for 문을 사용해 월초 일자별 신호가 발생한 종목에 포지션을 기록한다. 이렇게 포지셔닝을 해놓고 두번째로 만든 tradings() 함수를 통해 트레이딩을 진행하게 된다.
- create_trade_book() 함수
def create_trade_book(sample, sample_codes):
book = pd.DataFrame()
book = sample[sample_codes].copy()
book['STD_YM'] = book.index.to_period(freq='M')
for c in sample_codes:
book['p '+c] = ''
book['r '+c] = ''
return book
- tradings() 함수
def tradings(book, s_codes):
std_ym = ''
buy_phase = False
for s in s_codes:
print(s)
for i in book.index:
if book.loc[i, 'p '+ s] == '' and book.shift(1).loc[i, 'p '+s] == 'ready ' +s:
std_ym = book.loc[i, 'STD_YM']
buy_phase = True
if book.loc[i, 'p '+ s] == '' and book.loc[i, 'STD_YM'] == std_ym and buy_phase == True:
book.loc[i, 'p '+ s] = 'buy ' + s
if book.loc[i, 'p '+ s] == '':
std_ym = None
buy_phase = False
return book
마지막으로 거래 장부 book에 있는 거래를 가지고 상대 모멘텀 전략의 거래 수익률을 계산할 multi_returns() 함수를 아래와 같이 만든다.
def multi_returns(book, s_codes):
# 손익 계산
rtn = 1.0
buy_dict = {}
num = len(s_codes)
sell_dict = {}
for i in book.index:
for s in s_codes:
if book.loc[i, 'p ' + s] == 'buy '+ s and \
book.shift(1).loc[i, 'p '+s] == 'ready '+s and \
book.shift(2).loc[i, 'p '+s] == '' : # long 진입
buy_dict[s] = book.loc[i, s]
# print('진입일 : ',i, '종목코드 : ',s ,' long 진입가격 : ', buy_dict[s])
elif book.loc[i, 'p '+ s] == '' and book.shift(1).loc[i, 'p '+s] == 'buy '+ s: # long 청산
sell_dict[s] = book.loc[i, s]
# 손익 계산
rtn = (sell_dict[s] / buy_dict[s]) -1
book.loc[i, 'r '+s] = rtn
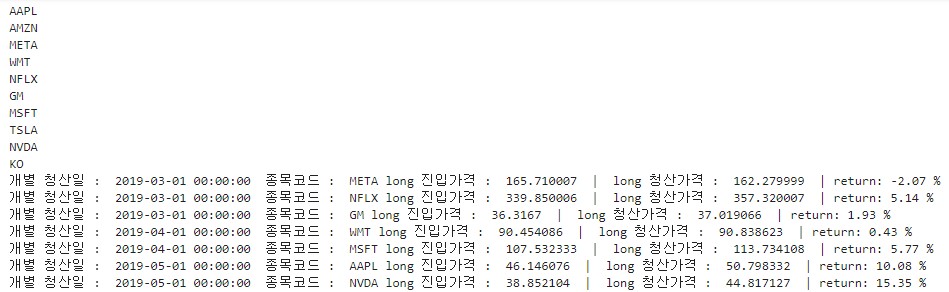
print('개별 청산일 : ',i,' 종목코드 : ', s , 'long 진입가격 : ', buy_dict[s], ' | long 청산가격 : ',\
sell_dict[s],' | return:', round(rtn * 100, 2),'%') # 수익률 계산.
if book.loc[i, 'p '+ s] == '': # zero position || long 청산.
buy_dict[s] = 0.0
sell_dict[s] = 0.0
acc_rtn = 1.0
for i in book.index:
rtn = 0.0
count = 0
for s in s_codes:
if book.loc[i, 'p '+ s] == '' and book.shift(1).loc[i,'p '+ s] == 'buy '+ s:
# 청산 수익률계산.
count += 1
rtn += book.loc[i, 'r '+s]
if (rtn != 0.0) & (count != 0) :
acc_rtn *= (rtn /count ) + 1
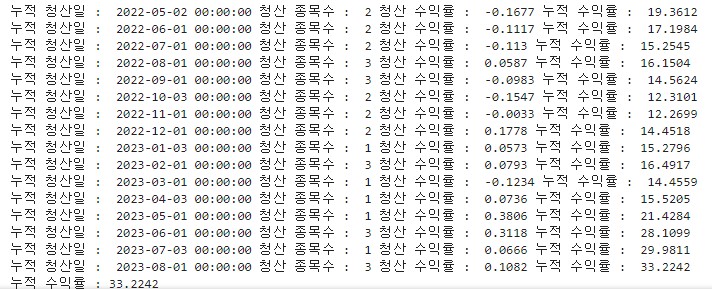
print('누적 청산일 : ',i,'청산 종목수 : ',count, \
'청산 수익률 : ',round((rtn /count),4),'누적 수익률 : ' ,round(acc_rtn, 4)) # 수익률 계산.
book.loc[i,'acc_rtn'] = acc_rtn
print ('누적 수익률 :', round(acc_rtn, 4))
상대 모멘텀 전략의 수익률은 다수 종목을 가지고 계산하므로 단일 종목으로 계산한 절대 모멘텀 전략의 수익률 계산과는 다른 것을 알 수 있다. 하지만, 절대 모멘텀 전략이나 상대 모멘텀 전략 모두 전에 보유하고 있던 포지션 여부를 검사한 후 그에 따라 진입과 청산, 유지를 결정하는 것이라는 기본적인 개념은 동일하다.
듀얼 모멘텀은 투자 자산 가운데 상대적으로 상승 추세가 강한 종목에 투자하는 상대 모멘텀 전략과 과거 시점 대비 현재 시점의 절대적 상승세를 평가한 절대 모멘텀 전략을 결합해 위험을 관리하는 투자 전략이다.
모멘텀(momentum)은 물질의 운동량이나 가속도를 의미하는 물리학 용어로, 투자 분야에서는 주가가 한 방향성을 유지하려는 힘을 의미한다.
듀얼 모멘텀 전략은 국내에서도 많은 미디어에 소개되며 대중에게 익숙한 퀀트 투자 전략이기도 하다.
듀얼 모멘텀 전략을 구현하기 위해서는 먼저 절대 모멘텀과 상대 모멘텀을 이해하고 구현할 수 있어야 한다.
최근 N개월간 수익률이 양수이면 매수하고 음수이면 공매도하는 전략을 절대 모멘텀 전략이라고 한다. 반면에 상대 모멘텀 전략은 투자 종목군이 10개 종목이라 할 때 10개 종목의 최근 N개월 모멘텀을 계산해 상대적으로 모멘텀이 높은 종목을 매수하고 상대적으로 낮은 종목은 공매도하는 전략이다.
이번에는 절대 모멘텀 전략을 실행해 보도록 한다.
절대 모멘텀 전략
먼저 필요한 라이브러리들을 가져오고, 분석할 데이터셋을 읽어온다.
import pandas as pd
import numpy as np
import FinanceDataReader as fdr
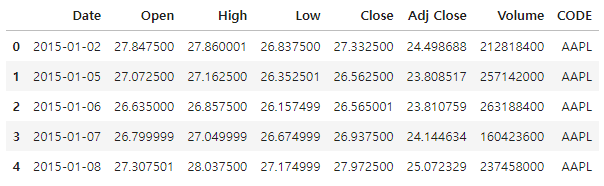
read_df = fdr.DataReader('SPY', '1993-01-29', '2023-09-12') # S&P 500 ETF 데이터를 가져옴.
read_df.head()
month_list = price_df['STD_YM'].unique()
month_last_df = pd.DataFrame()
for m in month_list:
# 기준 연월에 맞는 인덱스의 마지막 날짜 row를 데이터프레임에 추가
month_last_df = month_last_df._append(price_df.loc[price_df[price_df['STD_YM'] == m].index[-1], :])
month_last_df.head()
현재 데이터프레임에 있는 중복을 제거한 모든 '연-월' 데이터를 리스트에 저장해 월별 말일자에 해당하는 종가에 쉽게 접근할 수 있다.
월말 종가 데이터를 적재하는 별도의 데이터프레임을 만든다. 월말 종가 데이터 리스트를 순회하면서 index[-1]을 통해 월말에 쉽게 접근하고, 데이터를 추출해 새로 만든 데이터프레임에 적재한다. (append가 pandas 2.0부터 제거됨. _append로 사용가능)
판다스 DataFrame에서 제공하는 shift()함수를 이용하면 손쉽게 데이터를 가공할 수 있다. shift() 함수는 기본값이 period = 1, axis = 0으로 설정되지만, 입력 매개변수를 원하는 값으로 대체해 사용할 수 있다. 우리가 만든 데이터프레임에서 1을 지정하면 1개월 전 말일자 종가를 가져오고, 12를 넣으면 12개월 전 말일자 종가 데이터를 가져오게 할 수 있다. 데이터를 뒤로 밀어내는 것인데 초기 n개의 행에는 값이 없으므로 np.nan 값이 출력된다.
이제 모멘텀 지수를 계산해서 거래가 생길 때 포지션을 기록할 DataFrame을 만든다.
book = price_df.copy()
book['trade'] = ''
book.head()
반응형
최종적으로 기록된 포지션을 바탕으로 최종 수익률을 계산하는 데 사용된다. 처음에 만든 일별 종가가 저장된 DataFrame을 복사해 날짜 Date 컬럼을 index로 설정하고 거래가 일어난 내역을 저장할 Trade 컬럼을 만든다.
# trading 부분
ticker = 'SPY'
for x in month_last_df.index:
signal = ''
# 절대 모멘텀을 계산
momentum_index = month_last_df.loc[x, 'BF_1M_Adj Close'] / month_last_df.loc[x,'BF_12M_Adj Close']-1
# 절대 모멘텀 지표 True/False를 판단
flag = True if ((momentum_index > 0.0) and (momentum_index != np.inf) and (momentum_index != -np.inf)) else False and True
if flag :
signal = 'buy ' + ticker # 절대 모멘텀 지표가 Positive이면 매수 후 보유
print('날짜 : ', x, '모멘텀 인덱스 : ', momentum_index, 'flag : ', flag, 'signal : ', signal)
book.loc[x:, 'trade'] = signal
월별 인덱스를 순회하면서 12개월 전 종가 대비 1개월 전 종가 수익률이 얼마인지 계산한다. 계산된 수익률은 momentum_index 변수에 저장해 0 이상인지 확인하고, 0 이상이면 모멘텀 현상이 나타난 것으로 판단해 매수 신호가 발생하도록 한다. 이 부분을 flag 변수로 처리했다. 이어서 signal 변수에 저장된 매수 신호를 book 데이터프레임에 저장한다.
월말 종가를 기준으로 매수/매도 신호를 계산하므로 최소 1개월 이상 해당 포지션을 유지한다. 포지션을 유지하는 기간은 개인마다 다르지만 보통 1개월을 유지하기도 한다. 이를 전문 용어로 리밸런스 주기라고 한다.
그 다음으로 전략 수익률을 확인해 보자.
def returns(book, ticker):
# 손익 계산
rtn = 1.0
book['return'] = 1
buy = 0.0
sell = 0.0
for i in book.index:
if book.loc[i, 'trade'] == 'buy ' + ticker and book.shift(1).loc[i, 'trade'] == '' :
# long 진입
buy = book.loc[i, 'Adj Close']
print('진입일 : ', i, 'long 진입가격 : ', buy)
elif book.loc[i, 'trade'] == 'buy' + ticker and book.shift(1).loc[i, 'trade'] == 'buy ' + ticker:
# 보유중
current = book.loc[i, 'Adj Close']
rtn = (current - buy) / buy + 1
book.loc[i, 'return'] = rtn
elif book.loc[i, 'trade'] == '' and book.shift(1).loc[i, 'trade'] == 'buy ' + ticker:
# long 청산
sell = book.loc[i, 'Adj Close']
rtn = (sell - buy) / buy + 1 # 손익 계산
book.loc[i, 'return'] = rtn
print('청산일 : ', i, 'long 진입가격 : ', buy, ' | long 청산가격 : ', sell, ' | return: ', round(rtn, 4))
if book.loc[i, 'trade'] == '': # 제로 포지션
buy = 0.0
sell = 0.0
current = 0.0
acc_rtn = 1.0
for i in book.index :
if book.loc[i, 'trade'] == '' and book.shift(1).loc[i, 'trade'] == 'buy ' + ticker:
# long 청산시
rtn = book.loc[i, 'return']
acc_rtn = acc_rtn * rtn # 누적 수익률 계산
book.loc[i:, 'acc return'] = acc_rtn
print ('Accumulated return : ', round(acc_rtn, 4))
return (round(acc_rtn, 4))
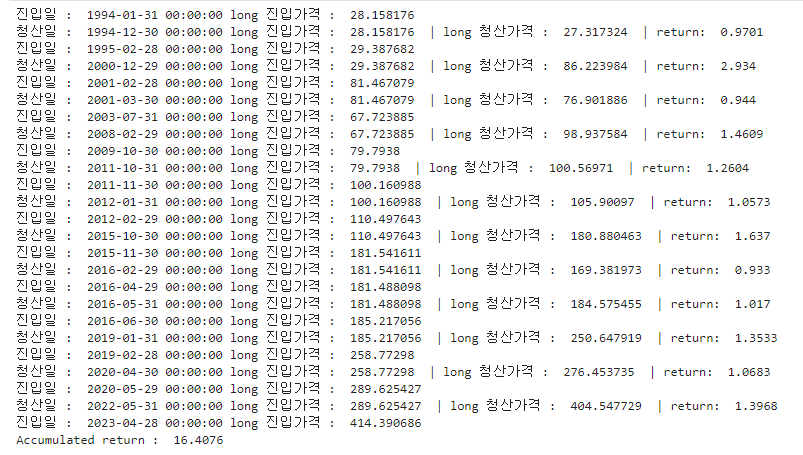
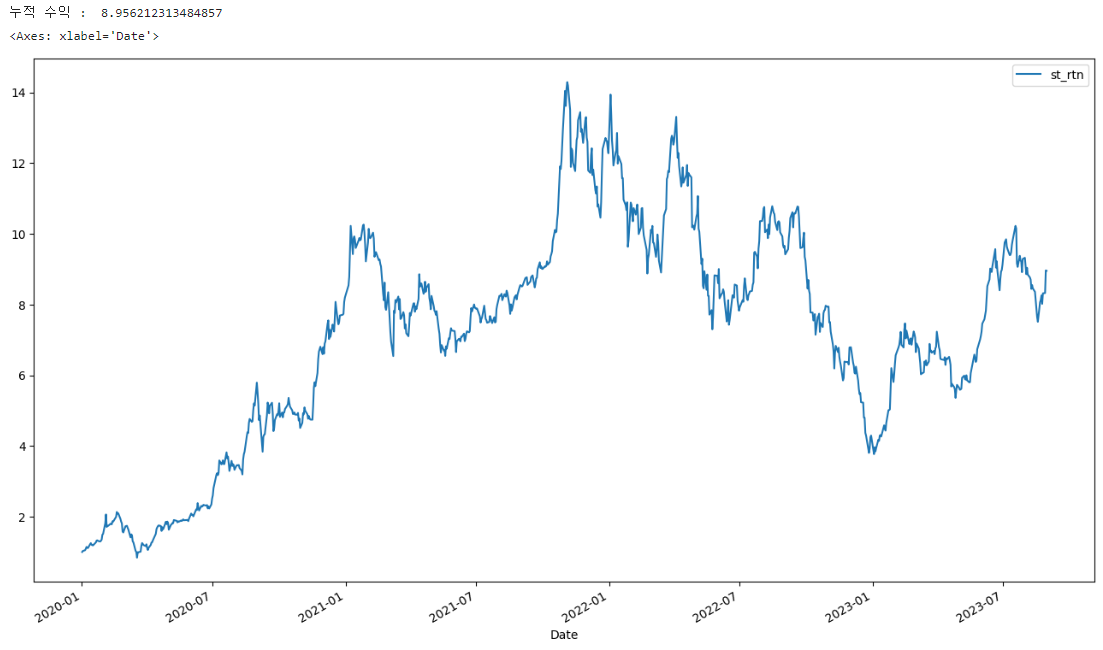
SPY ETF의 경우 12개월 전 대비 가격이 올랐을 때 매수하는 절대 모멘텀 전략의 수익률은 다음과 같다. 1에서 시작해 16.4076으로 종료되었으므로 1994년부터 2023년까지 1600%의 수익률을 낸 것이다.
지금까지 단일 종목을 절대 모멘텀 전략으로 구현해 보았다. 절대 모멘텀 전략은 종목별 자신의 과거 수익률을 기반으로 매수/매도 신호를 포착하므로 단일 종목으로도 구성할 수 있다.
퀀트Quant 투자를 달리 표현하면 데이터 기반 data-driven 전략이라고 할 수 있다.
퀀트는 정량적 방법론을 기반으로 투자 의사를 결정하는 것이며, 정량적 방법론이란 모든 것을 수치화하는 것을 의미한다.
사용하는 데이터에 따라 주가를 사용해 기술 지표를 만들고 이를 투자에 활용하는 '기술 지표 투자 전략'과 기업 재무제표를 사용하는 '가치 투자 전략', 이렇게 두 가지로 크게 나눌 수 있다.
주식 시장을 바라보는 트레이더의 시각에 따라 사용되는 지표는 다르다.
기술 지표를 활용한 퀀트 투자 전략 구현에서의 관건은 주가 데이터를 활용해 기술 지표를 만드는 것이다. 많은 파이썬 라이브러리에서 해당 기능을 제공하지만, 전략 확장성을 위해 수식을 기반으로 직접 만들어보는 것이 더 의미가 있다. 해당 지표들로 신호를 발생시켜 종목을 매매하고 전략의 수익률이나 승률 등을 살펴보는 방법도 알아본다.
기술 지표를 활용한 퀀트 투자 방법으로 모멘텀 전략과 평균 회귀 전략을 알아볼 것이다. 평균 회귀와 모멘텀은 서로 상반된 개념이다. 두 전략의 상관관계가 낮고 전략이 초점을 맞추는 시간대도 다르기 때문에 양극에 있는 두 방법을 살펴볼 가치는 충분하다고 볼 수 있다.
가치 투자 전략은 당기순이익, 영업이익, 영업이익률, 매출액, 부채비율, PER, PBR, PSR, PCR, ROE, ROA 등 기업의 가치 판단에 기준이 되는 재무제표 데이터를 기초로 한다.
가치 투자 전략에서는 기준이 되는 데이터에서 순위를 매겨 분위별로 자르는 작업이 훨씬 더 중요하다.
하지만 전략 평가는 기술 지표를 활용한 퀀트 투자 방법과 유사하다.
평균 회귀 전략
평균 회귀 (regression to mean)란 결과를 예측할 때 평균에 가까워지려는 경향성을 말한다. 한번 평균보다 큰 값이 나오면 다음번에는 평균보다 작은 값이 나와 전체적으로는 평균 수준을 유지한다는 의미다.
주식시장에서도 평균 회귀 현상이 통용되는지 검증하려는 많은 시도가 있었다. 이 현상에 의하면, 가격이 평균보다 높아지면 다음번에는 평균보다 낮아질 확률이 높다.
평균 회귀 속성을 이용한 전략을 들여다보면, 주가의 평균가격을 계산해 일정 범위를 유지하느냐 이탈하느냐에 따라 매매를 결정한다. 현재 주가가 평균가격보다 낮으면 앞으로 주가가 상승할 것으로 기대해 주식을 매수하고, 현재 주가가 평균가격보다 높으면 앞으로 주가가 하락할 것으로 예상해 주식을 매도하는 규칙을 설정할 수 있다.
볼린저 밴드 Bollinger band
볼린저 밴드는 현재 주가가 상대적으로 높은지 낮은지를 판단할 때 사용하는 보조지표다. 볼린저 밴드는 3개 선으로 구성되는데, 중심선은 이동평균 moving average 선, 상단선과 하단성을 구성하는 표준편차 standard deviation 밴드다.
볼린저 밴드를 사용하는 이유는 이동 평균선으로 추세를 관찰하고 상단선과 하단선으로 밴드 내에서 현재 가격의 상승과 하락폭을 정량적으로 계산할 수 있기 때문이다. 볼린저 밴드는 '추세'와 '변동성'을 분석해주어 기술 분석에서 활용도가 높으며 평균 회귀 현상을 관찰하는 데도 매우 유용하다. 보통 중심선을 이루는 이동 평균선을 계산할 땐 20일을 사용하고 상하위 밴드는 20일 이동 평균선 ± 2 * 20일 이동 표준 편차(σ)를 사용한다.
그럼 판다스를 사용해 볼린저 밴드 공식을 구현해 보도록 한다.
import pandas as pd
import FinanceDataReader as fdr
df = fdr.DataReader('AAPL', '1997-01-01', '2023-09-12') #애플 주식데이터를 가져온다.
df.head()
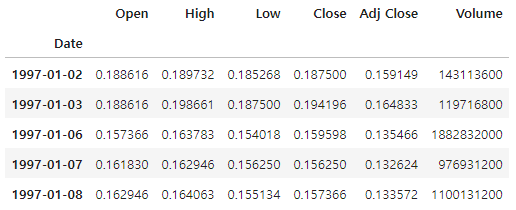
가장 먼저 해야할 작업은 데이터를 불러와 탐색해 보는 것이다. 애플('AAPL') 데이터를 실시간으로 불러와 df 변수에 저장한 후 head()함수를 통해 상위 5개 데이터를 확인한다. 인덱스는 날짜(Date)로 되어 있고, 각 컬럼은 시가(Open), 고가(High), 저가(Low), 종가(Close), 수정 종가(Adj Close), 거래량(Volume) 데이터로 구성된다.
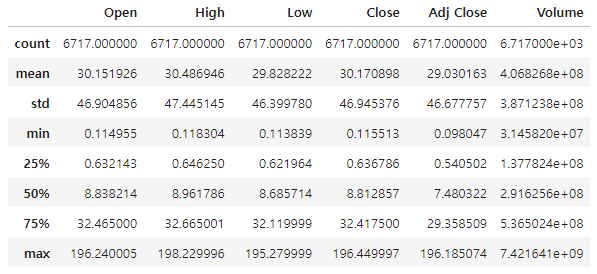
데이터프레임에 있는 describe() 함수를 사용해 데이터셋의 분포, 경향 분산 및 형태를 요약하는 정보를 확인할 수 있다.
iloc 인덱서를 사용해 18행부터 24행까지 어떤 값이 들어있는지 확인해 본다. 새롭게 만들어진 center 컬럼은 rolling()함수와 mean()함수로 계산된 20일 이동 평균선을 의미한다. rolling() 함수 특성상 window 입력값으로 20일을 주었기 때문에 데이터가 20개 미만인 부분은 결측치를 의미하는 NaN으로 표시된다.
일반적으로 결측치는 어쩔 수 없이 생성되기 때문에 볼린저 밴드에 필요한 기간보다 앞뒤로 더 많은 데이터(보통 쿠션 데이터 cushion data라고 부르는 여분의 데이터)를 추가하여 분석을 해야 한다. 실무에서는 생성하려는 자료를 고려해서 작성하는 것이 중요하지만, 여기서는 결측치가 발생한 행을 삭제한다.
def create_trade_book(sample):
book = sample[['Adj Close']].copy()
book['trade'] = ''
return(book)
이번에는 볼린저 밴드를 활용한 전략 알고리즘을 만들어 본다.
반응형
트레이딩 전략 알고리즘에 대한 전체 코드는 다음과 같다.
def tradings(sample, book):
for i in sample.index:
if sample.loc[i, 'Adj Close'] > sample.loc[i, 'ub']: # 상단밴드 이탈시 동작 안함
book.loc[i, 'trade'] = ''
elif sample.loc[i, 'db'] > sample.loc[i, 'Adj Close']: # 하단밴드 이탈시 매수
if book.shift(1).loc[i, 'trade'] == 'buy': # 이미 매수 상태라면
book.loc[i, 'trade'] = 'buy' # 매수상태 유지
else:
book.loc[i, 'trade'] = 'buy'
elif sample.loc[i, 'ub'] >= sample.loc[i, 'Adj Close'] and sample.loc[i, 'Adj Close'] >= sample.loc[i, 'db']: # 볼린저밴드 안에 있을 시
if book.shift(1).loc[i, 'trade'] == 'buy':
book.loc[i, 'trade'] = 'buy' # 매수상태 유지
else:
book.loc[i, 'trade'] = '' # 동작 안함
return (book)
이 전략의 특징은 장기 보유보다는 과매도 / 과매수 구간을 포착하는 단기 매매에 더 효과적이라고 해석한다.
완성된 거래 전략을 수행하면 다음과 같이 거래내역이 기록된 것을 확인할 수 있다.
book = tradings(sample, book)
book.tail(10)
다음은 트레이딩 book에 적혀있는 거래내역대로 진입/청산 일자에 따른 매수/매도 금액을 바탕으로 수익률을 계산해 보자.
def returns(book): # 손익계산
rtn = 1.000
book['return'] = 1
buy = 0.0
sell = 0.0
for i in book.index:
# long 진입
if book.loc[i, 'trade'] == 'buy' and book.shift(1).loc[i, 'trade'] == '':
buy = book.loc[i, 'Adj Close']
print('진입일 : ', i, 'long 진입가격 : ', buy)
#long 청산
elif book.loc[i, 'trade'] == '' and book.shift(1).loc[i, 'trade'] == 'buy':
sell = book.loc[i, 'Adj Close']
rtn = (sell-buy) / buy + 1 # 손익 계산
book.loc[i, 'return'] = rtn
print('청산일 : ', i, 'long 진입가격 : ', buy, '| long 청산가격 : ', sell, '| return:', round(rtn,4))
if book.loc[i, 'trade'] == '' : # 제로 포지션
buy = 0.0
sell = 0.0
acc_rtn = 1.0
for i in book.index:
rtn = book.loc[i, 'return']
acc_rtn = acc_rtn * rtn # 누적 수익률 계산
book.loc[i, 'acc return'] = acc_rtn
print('Accumulated return : ', round(acc_rtn, 4))
return (round(acc_rtn, 4))
수익률을 저장한 변수와 book변수에 수익률 컬럼을 만든다. for-loop문을 돌면서 포지션 여부에 따라 수익률을 계산해 데이터프레임에 저장하고, 최종적으로 누적 수익률을 계산한다.
print(returns(book))
변화 추이를 한눈에 보고 싶다면 누적 수익률을 그래프로 그려보자.
import matplotlib.pylab as plt
book['acc return'].plot()
백테스팅이라는 불리는 과정을 통해 실제 데이터를 가지고 확인을 해봐야 자신이 만든 전략의 신뢰도를 높일 수 있다. 여기서는 간단하게 과거 데이터를 통해 평균 회귀 전략에 대한 기본 개념을 정리해 본 것이다. 따라서, 이 전략을 바로 활용하기는 어렵다고 생각한다. 또한 평균 회귀 전략이 모든 종목에 적합한 것도 아니다. 그렇기 때문에 본인의 투자 철학과 해당 주식에 대한 면밀한 파악을 통해 전략을 수립하고 실행하도록 해야 한다.
컴퓨터 비전이나 텍스트 분석은 성능 좋은 오픈 API나 노하우가 축적되고 공유되어 빠르게 발전하고 있다. 하지만 투자 업계에서는 금융 데이터를 손쉽게 처리해주는 판다스 같은 라이브러리가 있어도, 성능 좋은 알고리즘이나 방법론이 공유되는 경우가 거의 없다.
세계 경제가 긴밀하게 연동하고 경제 주체들의 투자 패턴이 다양해짐에 따라 고려해야 할 변수가 기하급수적으로 증가한 반면 시계열 데이터를 기본으로 한 투자 데이터는 그 양이 한정적이다. 애널리스트 분석에 자주 사용되는 OECD 경기선행지수, 국가별 GDP, 금리 자료 등은 업데이트 주기가 길다. 이러한 데이터의 한계로 인해 좋은 모델을 만들기가 어렵다고 한다.
금융은 자본주의 사회에서 우리의 삶에 깊숙이 침투하여 개인의 일상생활과 밀접한 관계를 맺고 있고 우리가 살아가며 생산하는 수많은 데이터를 통해 연결되어 있다. 많은 의사결정 프로세스가 데이터 기반으로 전환하는 시대에 투자라고 예외일 수 없다. 나날이 복잡다단해지는 투자 환경에서 사람의 '감'에 기반한 투자 의사결정은 점점 힘을 잃어갈 것이다.
투자 영역에서 활용하는 데이터('실전 금융 머신러닝 완벽분석'의 저자인 마르코스 로페즈가 분류)
재무제표 데이터
마켓 데이터
분석 데이터
대체 데이터
자산
가격/변동성
애널리스트 추천
위성/CCTV 이미지
부채
거래량
신용 등급
구글 검색어
판매량
배당
이익 예측
트윗/SNS
비용/이익
이자율
감성 분석
메타데이터
거시 변수
상장/폐지
...
...
파이썬으로 만드는 투자전략과 주요 지표
1. 바이앤홀드(Buy & Hold) 전략
바이앤홀드는 주식을 매수한 후 장기 보유하는 투자 전략이다. 즉 매수하려는 종목이 충분히 저가라고 판단될 때 주기적으로 매수한 후 장기간 보유하는 식으로 투자하는 방법이다. 주가는 예측이 불가하지만 경제가 성장함에 따라 장기적으로 우상향한다는 투자 철학의 관점에서 보면 합리적인 투자 방법이다.
주피터 노트북(Jupyter notebook) 환경에서 실행한다고 가정하고, 관련 라이브러리를 다음과 같이 설치해야 한다.
!pip install matplotlib
!pip install pandas
!pip install -U finance-datareader # 국내 금융데이터를 포함 pandas-datareader를 대체
준비가 되면, 관련 라이브러리를 불러온다
import pandas as pd
import numpy as np
import FinanceDataReader as fdr
본격적으로 바이앤홀드 전략을 구현해 보자. FinanceDataReader 라이브러리에서 직접 테슬라(TSLA) 데이터를 추출하여, 판다스의 head()함수를 사용해 데이터를 살펴본다.
수정 종가(Adj Close)로 DataFrame을 만들고 종가(Close) 모양이 어떻게 생겼는지 그래프를 통해 살펴본다. 전체 기간을 보면 주가가 많이 상승했다. 하지만 짧은 시점을 확인해 보면 다를 수 있다. 테슬라는 최근 2022~2023년에 주가 변동성이 매우 큰 것을 알 수 있다.
우리가 가진 데이터셋의 마지막 날짜가 2023년 8월 30일이다. 해당일자의 최종 누적 수익률의 누적 연도 제곱근을 구하는 것이다. 또한 우리는 일(Daily) 데이터를 사용했으므로 전체년도를 구하기 위해 전체 데이터 기간을 252(금융공학에서 1년은 252 영업일로 계산)로 나눈 역수를 제곱(a**b) 연산한다. 그리고 -1을 하면 수익률이 나온다.
- 최대 낙폭(MDD)
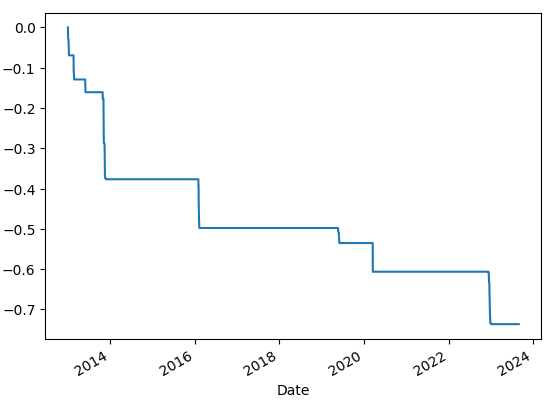
최대 낙폭은 최대 낙폭 지수로, 투자 기간에 고점부터 저점까지 떨어진 낙폭 중 최댓값을 의미한다. 이는 투자자가 겪을 수 있는 최대 고통을 측정하는 지표로 사용되며, 낮을수록 좋다.
수정 종가에 cummax() 함수 값을 저장한다. cummax()는 누적 최댓값을 반환한다. 전체 최댓값이 아닌 행row별 차례로 진행함녀서 누적 값을 갱신한다. 현재 수정 종가에서 누적 최댓값 대비 낙폭률을 계산하고 cummin() 함수를 사용해 최대 하락률을 계산한다. 출력 그래프를 보면 최대 하락률의 추세를 확인할 수 있다.
- 변동성(Vol)
주가 변화 수익률 관점의 변동성을 알아보자. 변동성은 금융 자산의 방향성에 대한 불확실성과 가격 등락에 대한 위험 예상 지표로 해석하며, 수익률의 표준 편차를 변동성으로 계산한다.
만약 영업일 기준이 1년에 252일이고 일별 수익률의 표준 편차가 0.01이라면, 연율화된 변동성은 다음 수식과 같이 계산된다.
콘솔 창에서 위 jupyter notebook --generate-config를 입력하면, jupyter_notebook_config.py 파일이 생성된다. 우분투의 ls -al 명령을 실행하면 현재 위치에 있는 폴더 목록(숨김 폴더까지 보여줌)을 보여준다. * 아래는 주피터 노트북 사이트에 나온 내용을 정리함
1. 단일 노트북 서버 실행
주피터 노트북 웹 애플리케이션은 서버-클라이언트 구조를 기반으로 한다. 노트북 서버는 HTTP 요청을 처리하기 위해 ZeroMQ와 Tornado를 기반으로 하는 2-프로세스 커널 아키텍처를 사용한다. ※ 기본적으로 노트북 서버는 127.0.0.1:8888에서 로컬로 실행되며 localhost에서만 액세스할 수 있다. http://127.0.0.1:8888을 사용하여 브라우저에서 노트북 서버에 액세스할 수 있다.
2. 공개 노트북 서버 실행
웹 브라우저를 통해 원격으로 노트북 서버에 액세스하려면 공용 노트북 서버를 실행하면 된다. 공용 노트북 서버를 실행할 때 최적의 보안을 위해서는 먼저 노트북 서버 보안을 해야 한다.
비밀번호와 SSL/HTTPS로 서버를 보호해야 한다.
먼저 비밀번호를 사용해서 노트북 보안을 하려면 다음과 같은 명령어를 입력하면 된다.
jupyter notebook password
노트북 서버 보안을 위해 인정서 파일과 해시된 비밀번호 생성하는 것부터 시작한다.
아직 구성 파일이 없으면 다음 명령줄을 사용해 노트북용 구성 파일을 만든다.
jupyter notebook --generate-config
~/.jupyter 디렉토리에서, jupyter_notebook_config.py 구성 파일을 편집한다. 기본적으로 노트북용 구성파일은 모든 필드가 주석처리되어 있다. 사용하려는 명령어 옵션만 사용가능하게 주석 처리를 해제하고, 편집해야 한다. 최소한의 구성 옵션 세트는 다음과 같다.
# 인증서 파일, IP, 비밀번호에 대한 옵션을 설정하고 브라우저 자동 열기를 끕니다.
c.NotebookApp.certfile = u'/absolute/path/to/your/certificate/mycert.pem'
c.NotebooApp.keyfile = u'/absolute/path/to/your/certificate/mykey.key'
# 공용 서버의 모든 인터페이스(ips)에 바인딩하려면 ip를 '*'로 설정합니다.
c.NotebookApp.ip = '*'
c.NotebookApp.password = u'sha1:bcd259ccf...<your hashed password here>'
c.NotebookApp.open_brower = False
# 서버 액세스를 위해 알려진 고정 포트를 설정하는 것이 좋습니다.
c.NotebookApp.port = 9999
그런 다음 jupyter notebook 명령어를 사용하여 노트북을 시작할 수 있다.
'https를 사용하세요. SSL 지원을 활성화했을 땐, 일반 http://가 아닌 https://를 사용해 노트북 서버에 접속해야 한다는 것을 기억하세요. 콘솔의 서버 시작 메시지에 이 내용을 미리 알려주만 세부 사항을 간과하고 서버가 다른 이유로 응답하지 않는다고 생각하기 쉽습니다.
SSL을 사용하는 경우 항상 'https://'로 노트북 서버에 접속!
이제 브라우저에서 공개 서버의 도메인 'https://your.host.com:9999'를 입력하여 당신의 공개 서버에 액세스할 수 있다.
반응형
3. 방화벽 설정
올바르게 작동하게 하려면, 클라이언트에서 연결할 수 있도록주피터 노트북 서버가 돌아가는 컴퓨터 방화벽(공유기가 있는 경우 공유기 방화벽 설정도 필요)의 주피터 노트북 구성 파일(jupyter_notebook_config.py)의 액세스 포트(c.NotebooApp.port) 설정에 구성되어 있어야 한다. 방화벽은 49152에서 65535까지의 포트에서 127.0.0.1(localhost)의 연결을 허용해야 한다. 이러한 포트는 서버가 노트북 커널과 통신하는 데 사용된다. 커널 통신 포트는 ZeroMQ에 의해 무작위로 선택되며 커널당 여러 연결이 필요할 수 있으므로 광범위한 포트에 액세스할 수 있어야 한다.
머신러닝 이전에 했던 방식으로 Input된 대상을 구별하기 위한 특징들(features)을 사람들이 직접 찾아내서, 판단할 수 있는 로직을 코딩으로 작성하여 결과(Output)을 찾아내는 방식임.
2. Hand designed feature based machine learning
사람들이 특징들(features)을 찾아내고, 특징들에 대한 로직은 코딩 대신 머신러닝(Machine Learning)을 통해 만들어 결과(Output)을 찾아내는 방식임.
* 머신러닝(Machine Learning)에 대한 기본 이해
학습 단계1. 학습데이터 준비 (사람들이 직접 특징 정의하고 학습 데이터 생성을 위한 코딩 작업 수행) 1-1. 이미지 수집 → 1-2. 특징 정의 → 1-3. 학습 데이터 생성
학습 단계2. 모델 학습 : 최적의 연산 집합은 모든 Try 중에 Error가 제일 작은 것! (오차를 최소화하는 연산을 찾아내는 것이 핵심으로, Try&Error 방식으로 최적의 연산 집합을 찾아냄) 2-0. 예측 및 오차 :
3. Deep Learning
Deep&Wide Neuralnetwork : 엄청나게 많은 연산들의 집합, 자유도가 높아 연산들의 구조를 잡고 사용 구조 예) CNN, RNN, etc
※ Deep Learning(CV, NLP 차이)
Computer Vision : 두 단계로 크게 구분 1-1 이미지 수집 → 1-2 학습 데이터 생성
Natural Language Processing : 세 단계로 크게 구분(토큰화 과정 추가) 1-1 텍스트 수집 → 1-2 정의된 특징(토큰화, 의미분석에 용이한 토큰으로 쪼갬) → 1-3 학습 데이터 생성
반응형
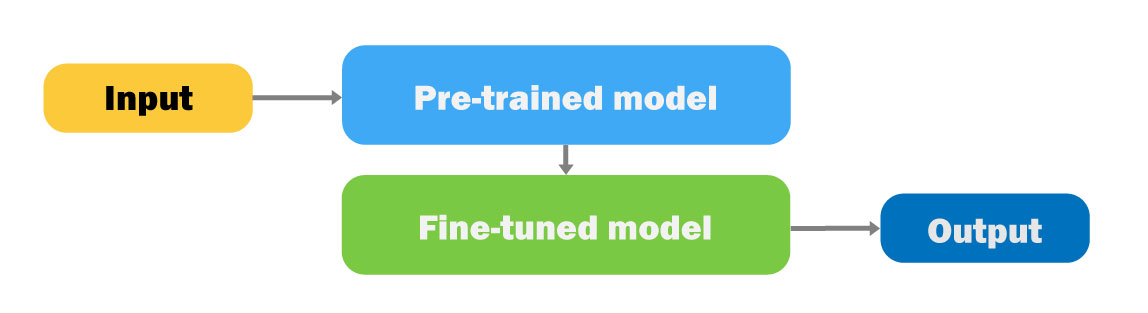
4. Pre-training & Fine-tuning (GPT)
기존의 딥러닝 문제점 : 분류 대상이 (태스크가) 바뀔 때마다 다른 모델이 필요
1단계 Pre-training : 모든 Image > Features > Mapping from features > 분류 결과(>1k)
2단계 Fine-tuning : 구분을 원하는 특정 이미지들을 입력
Image input > Features(1단계에서 학습된 연산을 고정(Frozen)한 상태) > Mapping from features(테스크를 수행하기 위해 mapping쪽에 해당하는 연산들만 새로 학습) > 특정 이미지 Output
여전히 태스크마다 다른 모델이 필요하지만, 필요한 데이터 수가 적어지고 개발 속도가 올라가게 됨!
5. Big Model & zero/few shot (ChatGPT 구조)
ChatGPT를 이해하기 위해 언어 모델(Language model)에 대한 이해가 선행되어야 함.
딥러닝 초창기의 언어 처리 모델은 “RNN” 아키텍쳐로 만들어짐
RNN(recurrent neural network), 노드 사이의 연결고리가 cycle을 이룬다고 해서 붙여진 이름으로, 자연어과 같은 sequence 형태의 데이터를 다루는데 특화되어 있음
단순한 다음 단어 맞추기가 ChatGPT롤 발전하게 된 계기?
Emergence(2017.4) :
OpenAI에서 Alec Radford가 언어 모델을 RNN으로 만들고 있었음
그런데 특정 뉴런이 감성 분석을 하고 있음을 발견함(긍정과 부정을 구분해 내는군)
언어 모델링을 하다보면 의도하지 않은 능력이 생기게 되는게 아닐까? > “Emergence”
Alec Radford는 GPT논문의 1저자
Transformer(2017.6) :
Transformer는 RNN, CNN과 유사한 아키텍처의 일종
“Attention”이란 항목과 항목 사이의 연관성
Transformer는 여러모로 성능이 좋았음. 계산 효율이 기존의 RNN 등에 비해 대단히 높았던게 이점, 게다가 결과의 품질도 더 좋음 > 이후 비전, 추천, 바이오 등 다른 모든 분야에서 쓰는 기술이 됨.
Alec Radford도 자연스럽게 Transformer를 가지고 실험하기 시작함.
GPT(2018.6) :
Alec Radford와 동료인 Ilya Sutskever 등이 RNN에서 Transformer로 넘어가며 출판
“Generative pretraining(GP)”을 하는 Transformer(T)
Pretraining-finetuning 패러다임의 대표적인 논문 – 큰 스케일에서 언어 모델링을 통해 사전학습 모델을 만들고, 이 모델을 파인튜닝하면 다양한 NLP 태스크에서 좋은 성능을 보임.
GPT-2(2019.2) :
Ilya Sutskever가 오랫동안 주장했던 믿음은 “데이터를 많이 부어 넣고 모델 크기를 키우면 신기한 일들이 일어난다”였음
Transformer 전까지는 큰 모델의 학습을 어떻게 할 것인가가 문제였는데, Transformer가 계산 효율이 높아 스케일링에 유리
모델을 키우고(117M > 1.5B)데이터를 왕창 부음(4GB > 40GB) -> GPT-2의 탄생
생성에 너무 뛰어나서 해당 모델이 가짜 정보를 다량 생성할 위험성이 크다고 판단, OpenAI는 GPT-2를 공개하지 않는다고 함
언어 생성을 아주 잘하게 될 뿐더러 emergence!가 또 보임
GPT2는 방대한 데이터를 기반으로 세상에 대해 많이 배운 모델
emergence!:Zero-shot learning : 예시를 전혀 보지 않고, 모델 업데이트 없이 새로운 태스크를 수행 “Unsupervised multitask learners, 하나를 가르쳤는데 열을 아네” 독해, 번역, 요약 Q&A 등에 대해 zero-shot 능력이 꽤 있음! Zero-shot인데도 특정 태스크는 기존의 SOTA 모델들을 짓눌러버림
SOTA란 state-of-the-art, 즉 현존하는 제일 좋은 모델
GPT-3(2020.6) :
여기서 한 번 더 크기를 키운 것이 GPT-3(모델 1.5B > 175B, 데이터 40GB > 600GB+)
많은 데이터로 pretraining해서 더욱 놀라운 생성 능력을 갖추게 됨
역시 여러 측면으로 “emergence”를 확인:
지식을 포함?(world knowledge), 학습 없이 태스크를 배우는 능력?(few-shot learners)
“Emergence”: In-context learning, Few-shot도 모델 파인튜닝 없이 되네? : 프롬프트에 예시 몇 개(“few-shot”)를 넣어주면 모델 업데이트 없이 새로운 태스크를 수행
GPT-4 출현 :
CLIP(2021.1) : “zero-shot” 이미지 분류
DALL-E(2021.1): 주어진 텍스트로부터 이미지 생성
Codex(2021.8) : 코드 생성을 위한 모델
InstructGPT(2022.1) : 명령에 대한 파인튜닝과 강화학습 > 이미 지식은 다 있다, 어떻게 뽑아낼 것인가
※ 위 정보는 fastcampus.co.kr의 업스테이지 '모두를 위한 ChatGPT UP!'의 강의 내용에서 요약 정리한 것입니다. 구체적인 내용을 배우시려면 업스테이지 강의를 들으시면 많은 도움이 되실 겁니다!
데이터를 옮기고 변경시켜서 어떤 작업을 수행하는데 있어 각종 작업을 자동화하여 프로그램을 만든 다음 cron(일정시간이 되면 특정 명령어를 실행하는 도구)같은 거에 실어서 주기적으로 실행하게 합니다. 그러다 이걸로도 충분하지 않은 상황이 된다면(복잡해지거나, 테스크가 변경되거나 등) 이런 시점에 WMS가 필요해집니다.
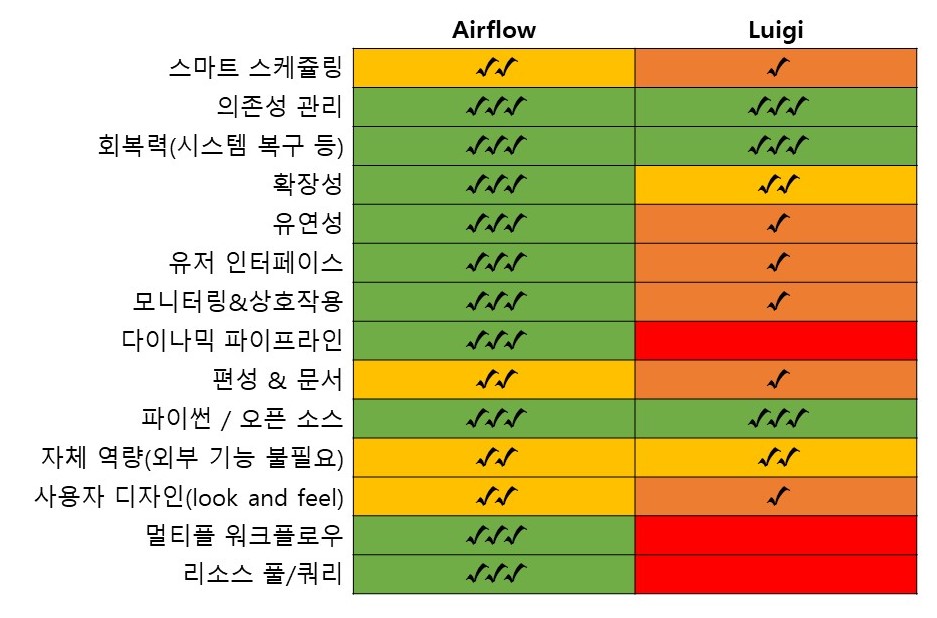
WMS도구 중 가장 유명한 2개 비교 ( Luigi & Airflow)
Luigi 는…
pipeline에 기반하였고, 각 task의 input/output은 정보를 공유하고 서로 연결된다.
Target기반 접근(Target은 Task의 결과물-통상 파일-)
UI는 꼭 필요한 기능만 단순하게 구현되었고, 프로세스를 실행하거나 하는 기능은 없다.
내장된 Trigger가 없다(crontab 파일을 편집해서 일정주기마다 실행되게 하는 식으로 구성해야 한단다)
분산 실행은 지원하지 않음(역주 : 병렬실행은 지원하지만…)
Airflow 는 …
DAG 표현에 기반
Task간 정보공유가 없으므로, 최대한 병렬화를 할 수 있단다(위상정렬/순서만 잘 정하면 된다)
Task간 통신 수단이 마땅치 않다.
설정하면 분산 실행할 수 있는 Executor가 있다
Scheduler가 있으므로, set it and forget it 할 수 있다(스스로 trigger한다)